SRE
- 体系化
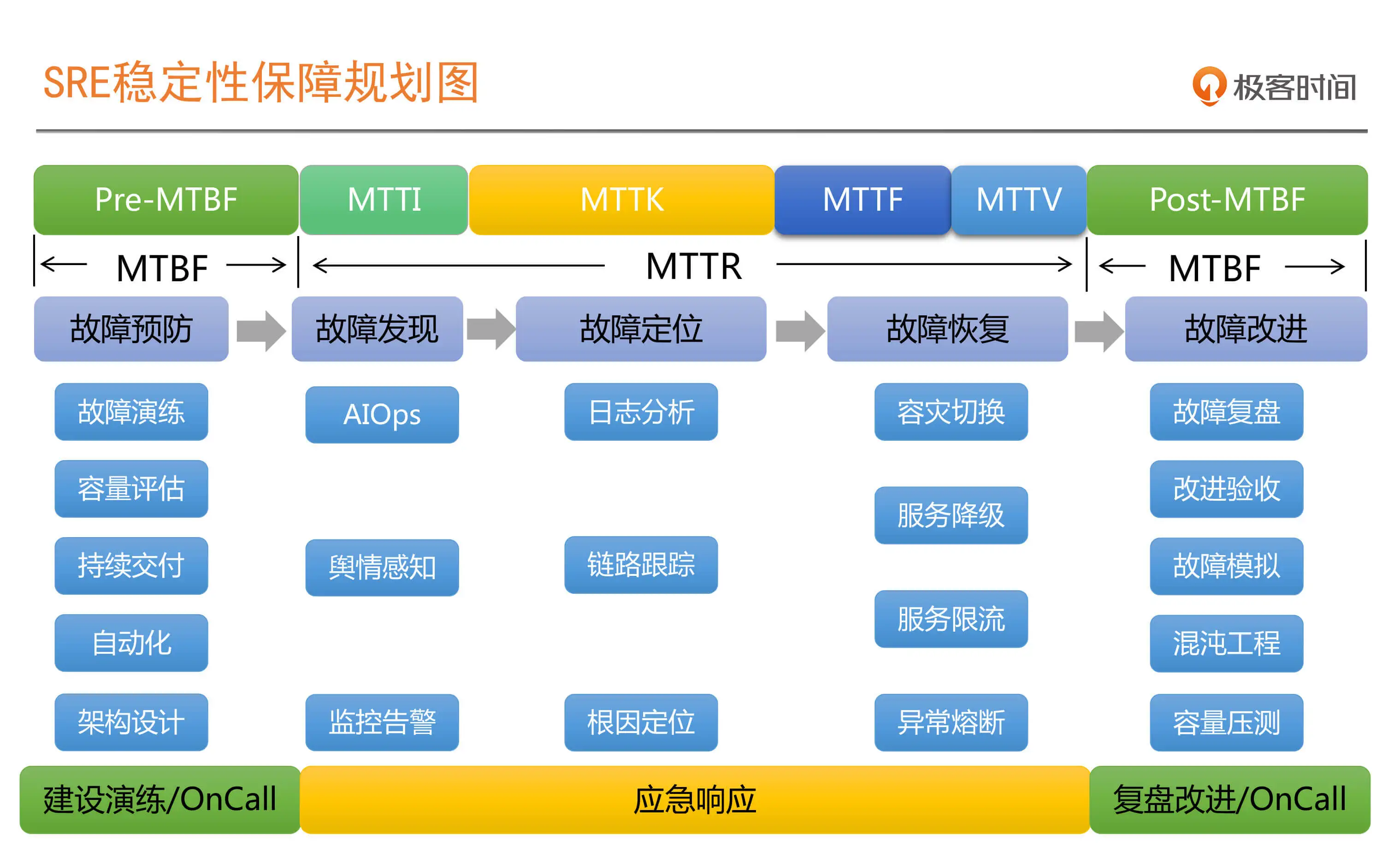
- MTBF,Mean Time Between Failure,平均故障时间间隔
- MTTR,Mean Time To Repair, 故障平均修复时间
- MTTI (Mean Time To Identify,平均故障发现时间),也就是从故障实际发生,到我们真正开始响应的时间。这个过程可能是用户或客服反馈、舆情监控或者是监控告警等渠道触发的
- MTTK (Mean Time To Know,平均故障认知时间),更通俗一点,可以理解为我们常说的平均故障定位时间。这个定位指的是root cause,,也就是根因被定位出来为止
- MTTF (Mean Time To Fix,平均故障解决时间),也就是从知道了根因在哪里,到我们采取措施恢复业务为止。这里采取的手段就很多了,比如常见的限流、降级、熔断,甚至是重启
- MTTV (Mean Time To Verify,平均故障修复验证时间),就是故障解决后,我们通过用户反馈、监控指标观察等手段,来确认业务是否真正恢复所用的时间。
SRE只有一个目标:提升 MTBF,降低 MTTR
可用性目标
衡量维度:
- 时间维度:Availability = Uptime / (Uptime + Downtime)
- 请求维度:Availability = Successful request / Total request
这两种算法最后都会落脚到“几个 9”上
需要考虑:
- 成本因素:越高的可用需要越高的投入,要先考虑 ROI(回报率)
- 业务容忍度:对于越核心的系统,容忍度越低
- 系统当前的稳定状况:定一个合理的标准比定一个更高的标准会更重要
稳定性衡量标准
- SLI,Service Level Indicator,服务等级指标,选择哪些指标来衡量我们的稳定性
- SLO,Service Level Objective,服务等级目标,设定的稳定性目标
SLI的选择
- 够标识一个主体是否稳定
- 优先选择与用户体验强相关或用户可以明显感知的指标
快速识别 SLI 指标的方法:VALET:
- Volume 容量:服务承诺的最大容量是多少。比如,一个应用集群的 QPS、TPS、会话数以及连接数等
- Availablity 可用性:代表服务正常与否
- Latency 时延:有针对性地取置信区间内的延迟,而非简单的平均,否则会使问题被隐藏在平均之下
- Errors 错误率
- Tickets 人工介入频次:一项工作或任务需要人工介入,那说明一定是低效或有问题的
在云服务中提供商SLA中,很少能制定像 SLO 这么细粒度稳定性目标,更多的是使用简单的可用性衡量:成功请求数/总请求数 这种
SLO的设定
- 核心应用的 SLO 要更严格,非核心应用可以放宽
- 核心应用的直接依赖,SLO要一致
- 弱依赖中,核心应用对非核心的依赖,要有降级、熔断和限流等服务治理手段
- 核心应用的错误预算要共享,就是如果某个核心应用错误预算消耗完,SLO 没有达成,那整条链路,原则上是要全部暂停操作
SLO的验证:
错误预算
在 SLO 落地实践时,SLO 可以被转化为错误预算,即你有多少次出问题的机会,以此来推进稳定性目标达成,为了达成 SLO,就要尽量减少对错误预算的消耗
当错误预算还很多,对异常及错误容忍就比较高,当错误预算快要被耗尽了,就应该尽量解决问题,减少或拒绝变更
故障发现
第一件事,判断出现的问题是不是故障;第二件事,确定由谁来响应和召集
即建立完善的监控体系及 On-Call 机制
On-Call 的流程机制建设:
- 确保关键角色在线
- 组织 War Room 应急组织
- 建立合理的呼叫方式,进行On-Call轮班
- 确保资源投入的升级机制,授权非常关键
- 与云厂商联合的 On-Call
故障处理
有效的故障应急响应机制:
- 角色分工:指挥核心、内外信息收集通报、运维指挥操作、其他人员(事故相关方)
- 流程机制:快速组织救火队,以恢复业务为最高优先级,如果问题疑难,必须向上抛
- 反馈机制:定时汇报进度,不管有没有,防止故障继续蔓延
故障复盘
- 故障原因有哪些?
- 我们做什么,怎么做才能确保下次不会再出现类似故障?
- 当时如果我们做了什么,可以用更短的时间恢复业务?
由谁来承担主要的改进职责-故障判定三原则:
- 健壮性原则:每个部件自身要具备一定的自愈能力,做好对外部依赖的防御
- 第三方默认无则:外部是不可靠的,还是做好防御
- 分段判定原则:根因不止一个