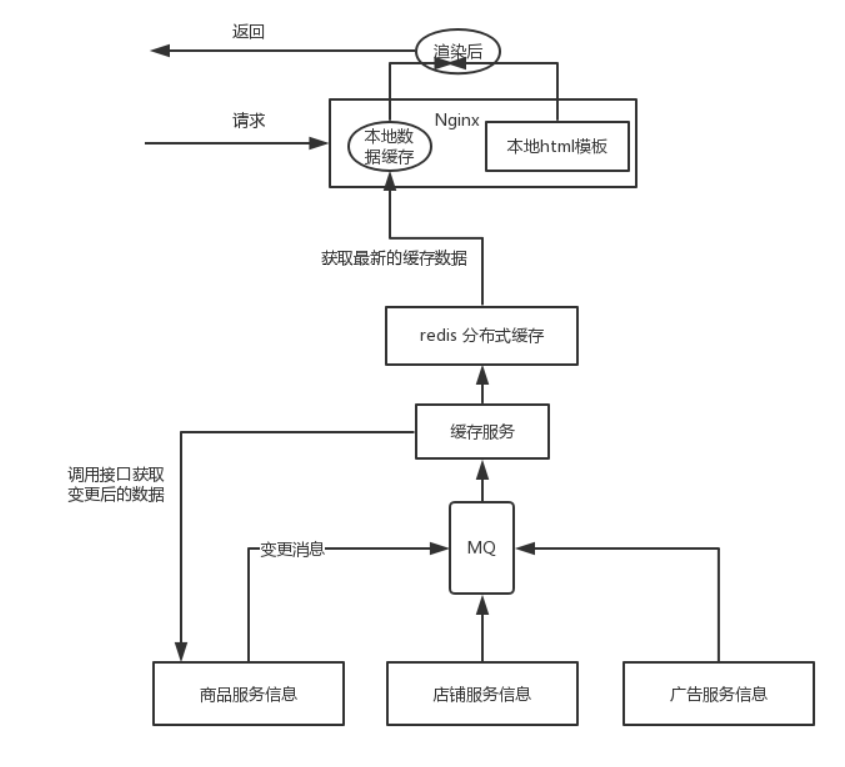
缓存
为什么使用
收益:
- 加速读写:缓存通常都是全内存的(缓解IO压力)
- 降低后端负载:帮助后端减少访问量和复杂计算(缓解CPU压力)
成本:
- 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致
- 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑
- 运维成本:如Redis集群的加入 运维会更有难度
缓存方案设计考虑点
- 什么数据应该缓存
- 什么时机触发缓存和以及触发方式是什么
- 缓存的层次和粒度( 网关缓存如 nginx,本地缓存如单机文件,分布式缓存如redis cluster,进程内缓存如全局变量)
- 缓存的命名规则和失效规则
- 缓存的监控指标和故障应对方案
- 可视化缓存数据如 redis 具体 key 内容和大小
特征
吞吐量
使用OPS值(每秒操作数,Operations per Second,ops/s)来衡量,反映了对缓存进行并发读、写操作的效率
在并发读写的场景下, 避免竞争是最关键的
命中率
某个请求能够通过访问缓存而得到响应时,称为缓存命中率
缓存命中率越高,缓存的利用率也就越高
最大空间
缓存的利用空间是有限的
当缓存存放的数据量超过最大空间时,就需要淘汰部分数据来存放新到达的数据
分布式支持
缓存可分为“进程内缓存”和“分布式缓存”两大类
- 复制式缓存:每个节点里面都存在有一份副本,读取数据时无需网络访问,直接从当前节点的进程内存中返回,当数据发生变化时,就必须遵循复制协议,将变更同步到集群的每个节点中,这种复制性能随着节点的增加呈现平方级下降,变更数据的代价十分高昂
- 集中式缓存:是目前分布式缓存的主流形式,集中式缓存的读、写都需要网络访问,其好处是不会随着集群节点数量的增加而产生额外的负担,其坏处自然是读、写都不再可能达到进程内缓存那样的高性能。由于对象更新一个字段可能也会导致整个对象的序列化传输,所以集中式缓存更提倡缓存原始类型
使用多级缓存同时得到两种类型的优点:
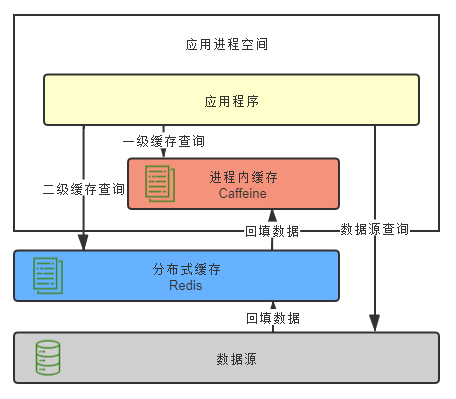
在JVM进程内一级的缓存若过大 可能会造成GC压力过大 此时使用堆外内存分配能有效提升性能
集中式缓存高可用
- 客户端方案:在客户端完成缓存分片、负载均衡等操作
- 中间代理层:读写请求都是经过代理层完成的。代理层是无状态的,主要负责读写请求的路由功能,并且在其中内置了一些高可用扩展,Facebook 的Mcrouter,Twitter 的Twemproxy,豌豆荚的Codis
- 服务端方案:一般就是缓存中间件自带的,Redis的哨兵,Redis的集群
扩展功能
更新策略
当缓存使用量超过了预设的最大值时候 FIFO(先进先出) LRU(最久未使用) LFU(最少使用) 等算法用来剔除部分数据 数据一致性最差(因为数据的过期完全取决于缓存) 但基本没有维护成本
针对LRU的一些缺点,出现了一些算法,这些算法在某些条件下往往有更好的表现:
- TinyLFU:会用少量的样本数据来估计全体数据的特征,并且每隔一段时间,便会把计数器的数值减半,以此解决“旧热点”数据难以清除的问题
- W-TinyLFU:用来解决TinyLFU无法应对稀疏突发访问的问题
超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除 段时间窗口内(取决于过期时间长短)存在一致性问题 维护成本不高 只需要设置一个过期时间
应用方对于数据的一致性要求高,需要在真实数据更新后,立即主动更新缓存数据 一致性很高 但是维护成本也是最高的
缓存粒度
究竟是缓存全部属性还是只缓存部分重要属性呢 从三个维度判断:
- 通用性:缓存全部数据比部分数据更加通用 但是数据具有热点 一般只有几个属性用的比较多
- 空间带宽。缓存全部数据要比部分数据占用更多的空间及带宽
- 代码维护:部分数据一旦要加新字段需要修改业务代码
位置
- 浏览器缓存
- CDN
- ISP缓存
- ISP是网络访问的第一跳,这个地方有缓存能大大加快用户的访问速度
- 反向代理缓存
- 本地缓存
- 这里指的是将缓存存放在服务器进程内
- 分布式缓存
- 使用专门的服务器集群来存放缓存
- 数据库缓存
- 一般数据库都有自己的缓存机制
- CPU缓存
读写策略
旁路
sequenceDiagram
客户端 ->> 数据库: 更新数据库
客户端 ->> 缓存: 删除缓存
客户端 ->> 缓存: 查询缓存未命中
客户端 ->> 数据库: 查询数据库
客户端 ->> 缓存: 回写缓存
读穿写穿
flowchart TB
请求 --> 写请求
写请求 --> |是| 写缓存命中
写缓存命中 --> |是| 写缓存
写缓存命中 --> |否| 写数据库
写缓存 --> 写数据库
写请求 --> |否| 读缓存命中
读缓存命中 --> |是| 返回数据
读缓存命中 --> |否| 数据库加载数据到缓存
数据库加载数据到缓存 --> 返回数据
写回
在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中
这种策略不能被应用到我们常用的数据库和缓存的场景中,主要是因为一旦缓存机器掉电,就会造成原本缓存中的脏块儿数据丢失,是底层中如磁盘或者页缓存使用的
缓存风险
缓存雪崩
在高并发的情况下吗,由于于数据没有被缓存中或者缓存都采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部发到数据库,数据库瞬时压力过重
解决方案
- 锁
- 比如对某个key只允许一个线程数据库查询数据和写缓存,其他线程等待
- 但是这样就只能限制同一时间只能有一个线程访问数据库,吞吐量还是不行
- 消息中间件
- 缓存中间件没有命中的情况下,生产者将缓存更新请求通过MQ发送给消费者,消费者通过自身的串行处理可以实现对缓存只写一次,后续的请求可以忽略掉
- 使用多级缓存以及分布式缓存
- 分析用户的行为,尽量让缓存失效的时间均匀分布(将过期时间上下浮动一定范围)
- 缓存预热:对于可预见的热点数据 进行缓存预先加载 避免突发大流量压垮数据库
概括:
- 保证缓存层服务的高可用
- 对后端服务进行限流降级 一旦后端服务不可用 直接降级返回一个友好结果
热点key
- 缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题:
如果这个key的计算不能在短时间完成,那么在这个 key 在效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞
解决方案
- 锁
- 在重建缓存时 只允许一个线程重建 其他线程必须等待
- 不设置过期时间,而将过期时间设置在数据中,如果检测到数据过期了,再清除掉 或者当发现超过逻辑过期时间后,会使用单独的线程去构建缓存
- 读写分离 使用如canal等中间件从数据库同步数据到缓存
缓存穿透
指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,请求穿透到了数据库,然后返回空。这样就会导致每次查询不存在的数据都会绕过缓存去查询数据库
解决
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透
- 这种方案对空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 同时也会有一定的数据不一致性
- 也可以使用布隆过滤器直接对这类请求进行过滤
- 这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景
布隆过滤器
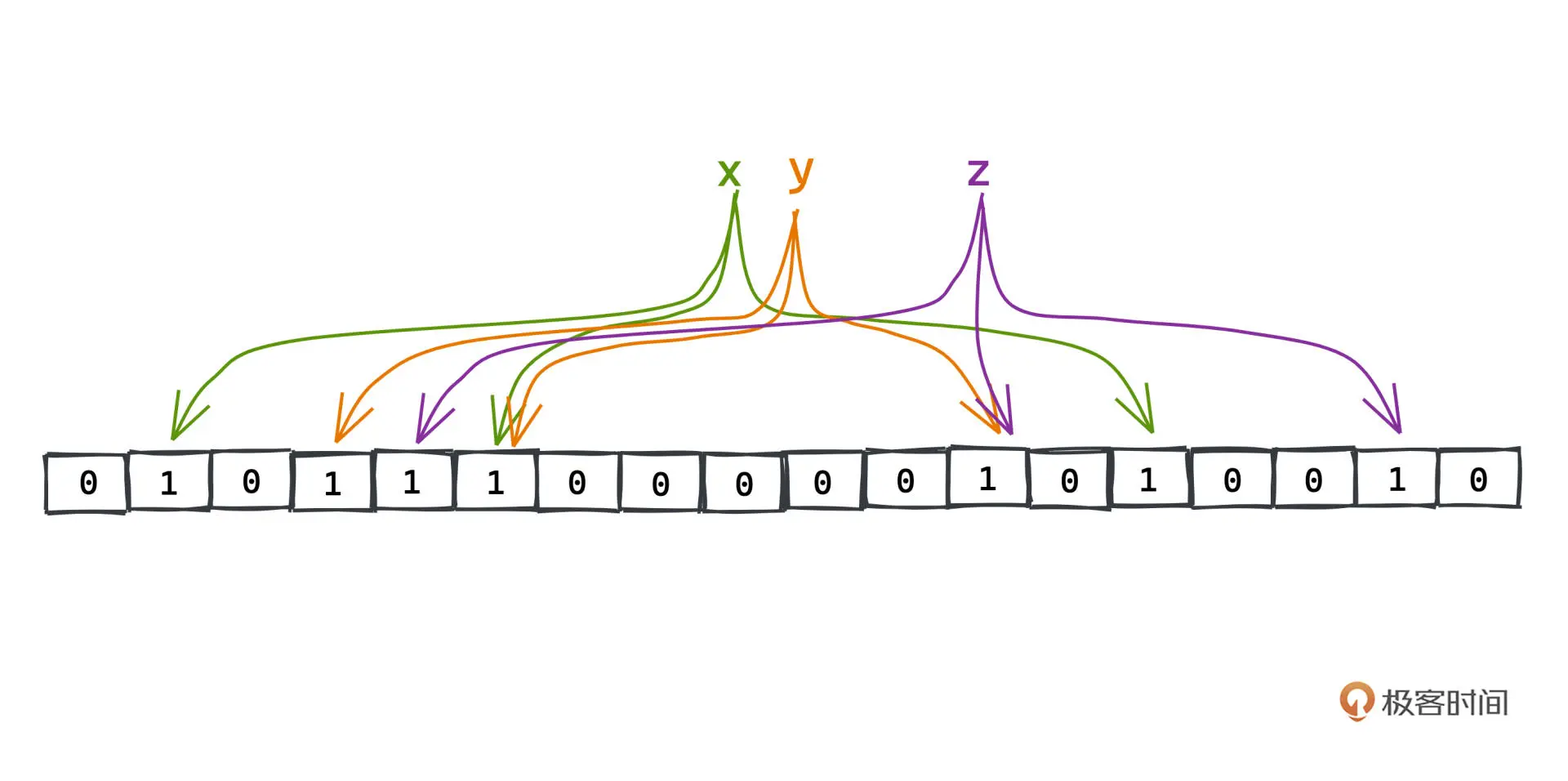
一串数据通过n个散列函数将一个位图的n位设置为1,当要查询时,对数据进行散列 判断对应的n位是否都为1 若为1, 则就是可能存在
所以布隆过滤器也没有足够的信息可以删除指定的key,为了应对缓存数据过期,可以采用定期重建的方法,重建完保持两个过滤器的双写,一段时间后,就把全部请求都给到较新的这个过滤器上,清除老的过滤器
布谷鸟过滤器
- 布谷鸟哈希:使用两个哈希函数对一个key进行哈希,得到桶中的两个位置,如果有空位,key就放在空位里,否则就要随机踢掉一个元素,踢出的元素再计算哈希找到相应的存储位置
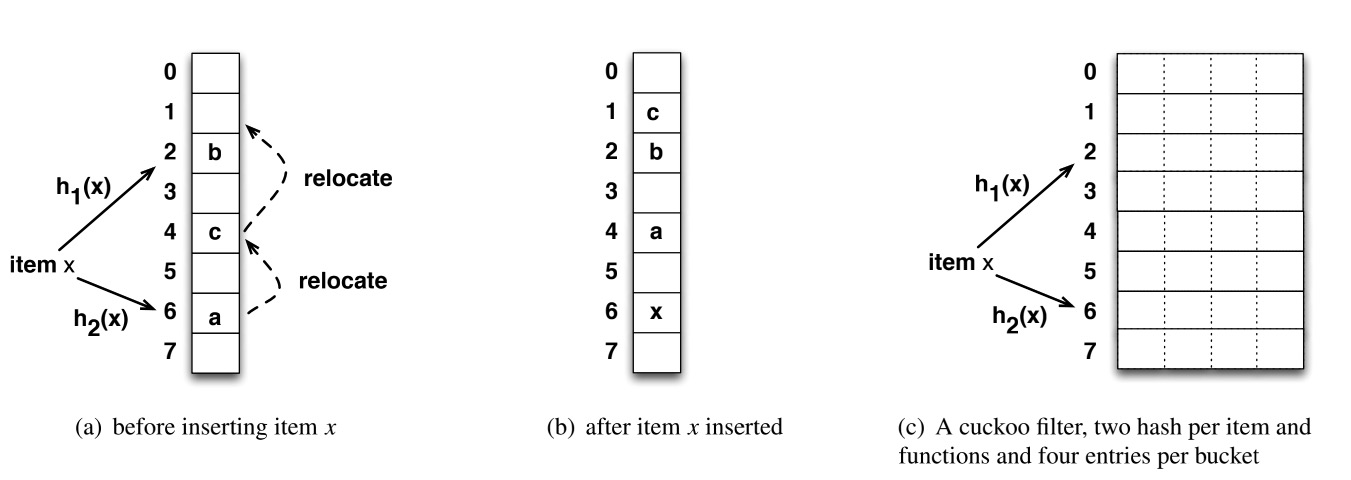
哈希表的基本单位称为条目(entry)。 每个条目存储一个指纹(fingerprint),指纹指的是使用一个哈希函数生成的n位比特位
相比布隆过滤器,布谷鸟过滤器可以通过从哈希表删除相应的指纹删除插入的项,由于哈希的特性,是存在误删的可能的,同时,只要不发生桶溢出,在查询的时候就不会出现假阳
缓存一致性
缓存中的数据与真实数据源中的数据不一致的现象
解决
- 当数据更新的同时立即去更新缓存
- 读请求和写请求串行化,串到一个内存队列里去
- 读缓存之前判断缓存是否是最新,否则先进行更新缓存
- 更新数据时,先更新数据库,再删除缓存(旁路写策略)
- 为什么要删除缓存,而非更新缓存,如果缓存采用更新的方式,可能这个缓存压根就不会被用到,应该是用到缓存才去写入缓存
保证缓存一致性需要付出很大的代价,缓存数据最好是那些对一致性要求不高的数据,允许缓存数据存在一些脏数据。或者直接使用类似于canal的中间件,直接同步数据库,这样不仅能解耦业务代码,也能拥有最终一致性
缓存无底洞
随着缓存节点数目的增加,键值分布到更多的节点上,导致客户端一次批量操作会涉及多次网络操作
解决
- 优化细粒度的远程调用
- 减少网络通信次数
- 使用长连接或者连接池
客户端缓存
浏览器缓存
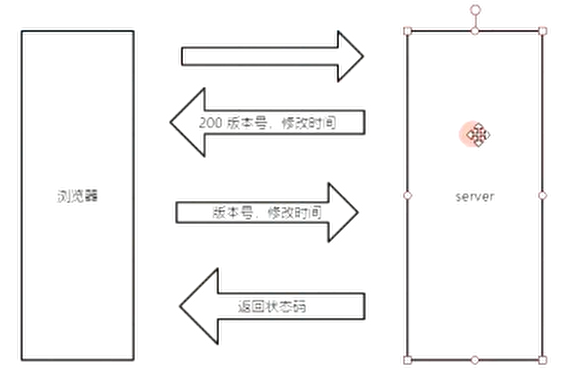
- ETag
ETag: "5d8c4a06-a0fc"
ETag 用来校验用户请求的资源是否有变化
- Cache-Control、 Last-Modified 、Expires
Last-Modified : 表示文档最后修改时间,浏览器在访问重复资源的时候会发送IF-Modified-Since 携带此时间去服务器验证,如果时间匹配则返回304,浏览器加载本地资源
Expires: 文档过期时间,在浏览器内可以通过这个时间来判断是否发送请求
Cache-Control :http1.1的规范,使用max-age表示文件可以在浏览器中缓存的时间以秒为单位
- Cache-Control和ETag的区别
Cache-Control直接是通过不请求来实现,而ETag是会发请求的,只不过服务器根据请求的东西的内容有无变化来判断是否返回请求的资源
Age
是CDN添加的属性表示在CDN中缓存了多少秒
via
用来标识CDN缓存经历了哪些服务器,缓存是否命中,使用的协议
浏览器缓存原则
首页可以看做是框架 应该禁用缓存,以保证加载的资源都是最新的
还有一些场景下我们希望禁用浏览器缓存。比如轮训api上报数据数据
浏览器缓存很难彻底禁用,大家的做法是加版本号,随机数等方法。
只缓存200响应头的数据,像3XX这类跳转的页面不需要缓存。
对于js,css这类可以缓存很久的数据,可以通过加版本号的方式更新内容
不需要强一致性的数据,可以缓存几秒
异步加载的接口数据,可以使用ETag来校验。
在服务器添加Server头,有利于排查错误
应用缓存
分为手机APP和Client以及是否遵循http协议
在没有联网的状态下可以展示数据
流量消耗过多
- 漂亮的加载过程
- 提前下发 避免秒杀时同时下发数据造成流量短时间暴增
- 兜底数据 在服务器崩溃和网络不可用的时候展示
- 临时缓存 退出即清理
- 固定缓存 展示框架这种,可能很长时间不会更新,可以随客户端下发
- 父子连接 页面跳转时有一部分内容不需要重新加载,可用从父菜单带过来
- 预加载 某些逻辑可用判定用户接下来的操作,那么可用异步加载那些资源
- 异步加载 先展示框架,然后异步加载内容,避免主线程阻塞
数据分布
哈希分布
哈希分布就是将数据计算哈希值之后,按照哈希值分配到不同的节点上
传统的哈希分布算法存在一个问题:当节点数量变化时,那么几乎所有的数据都需要重新分布,将导致大量的数据迁移
顺序分布
将数据划分为多个连续的部分,每个节点固定存放一定范围内的数据,按数据的 ID 或者时间分布到不同节点上
可以保持数据的顺序,并且可以控制服务器的数据量
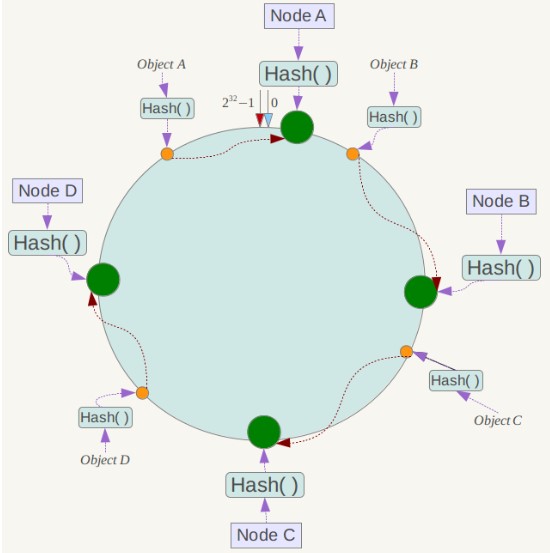
一致性哈希
Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题,当然不仅可以用在存储上,也能用在请求的负载均衡上
将哈希空间看做一个环,服务器节点分布在这些环上,当一个数据计算出哈希值后,找出这个哈希值后面最近的一台服务器,将数据存放到这台服务器上
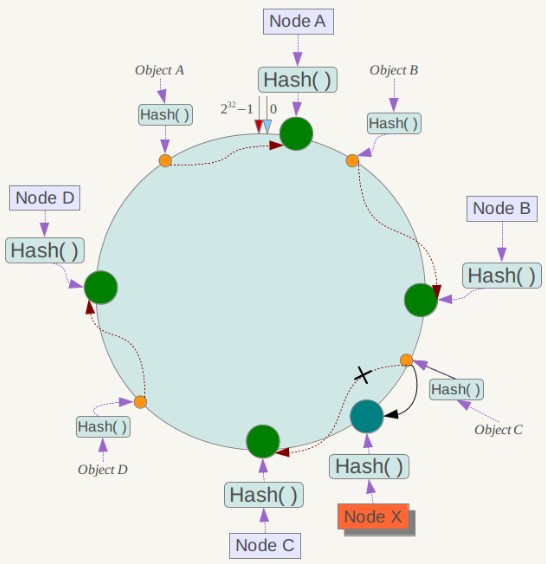
当服务器节点发生变更,受到影响的,只是变更节点的后一台服务器,只需对这台服务器的数据进行重新再计算哈希即可
虚拟节点
一致性哈希存在数据分布不均匀的问题,节点存储的数据量有可能会存在很大的不同
那么就可以通过增加虚拟节点的方式,把这些节点映射到真正的服务器节点,使得数据分布更加均匀
静态化
全量静态化
对于小型网站,页面不多,可以采用这个方式
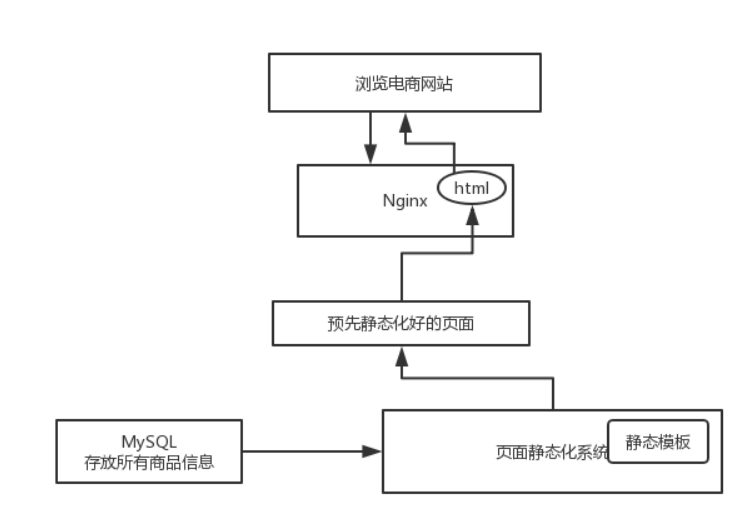
按需静态化
当数据发生变更,往MQ推送一条消息,消费者消费数据并进行渲染