IO
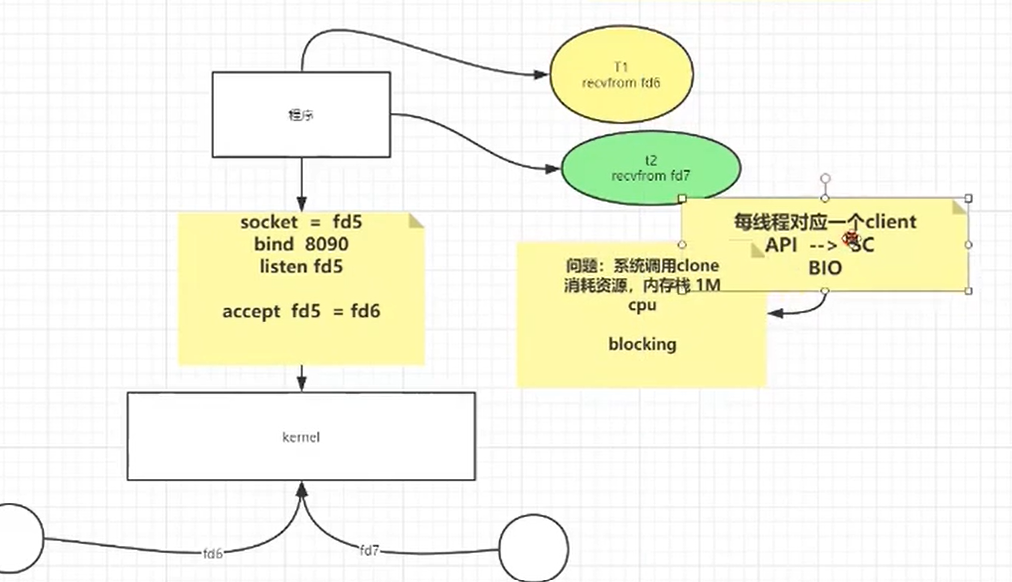
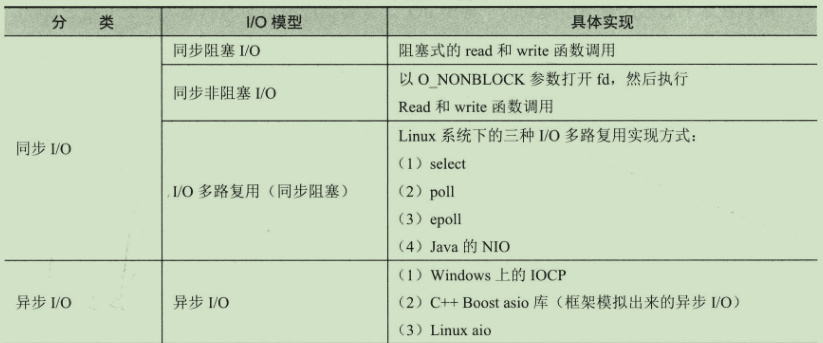
- BIO (Blocking I/O): 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成
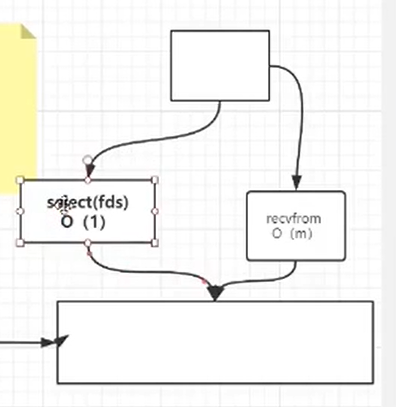
- NIO (Non-blocking/New I/O): NIO 是一种同步非阻塞的 I/O 模型,支持面向缓冲的,基于通道的 I/O 操作方法
- AIO (Asynchronous I/O):异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作
网络IO模型:
网络框架设计模式:
- Reactor模式:主动模式 应用程序不断轮询 询问底层IO是否准备就绪
- Proactor模式:被动模式 read write都交给底层 通过回调完成操作
服务器网络编程 1 + N + M 模型
1个监听线程 N个IO线程 M个worker线程
架构
stateDiagram-v2
direction LR
处理流 --> 缓冲操作
缓冲操作 --> BufferedInputStream
缓冲操作 --> BufferedOutputStream
缓冲操作 --> BufferedReader
缓冲操作 --> BufferedWriter
处理流 --> 基本数据类型操作
基本数据类型操作 --> DataInputStream
基本数据类型操作 --> DataOutputStream
处理流 --> 对象序列化操作
对象序列化操作 --> ObjectInputStream
对象序列化操作 --> ObjectOutputStream
处理流 --> 转化控制
转化控制 --> InputStreamReader
转化控制 --> OutputStreamWriter
处理流 --> 打印控制
打印控制 --> PrintStream
打印控制 --> PrintWriter
节点流 --> 文件操作
文件操作 --> FileInputStream
文件操作 --> FileOutputStream
文件操作 --> FileReader
文件操作 --> FileWriter
节点流 --> 管道操作
管道操作 --> PipedInputStream
管道操作 --> PipedOutputStream
管道操作 --> PipedReader
管道操作 --> PipedWriter
节点流 --> 数组操作
数组操作 --> ByteArrayInputStream
数组操作 --> ByteArrayOutputStream
数组操作 --> CharArrayReader
数组操作 --> CharArrayWriter
大体分为几类:
- 字节操作流 InputStream 与 OutputStream等
- 字符操作流 Writer 与 Reader
- 磁盘IO File
- 网络操作 Socekt等
节点流可以从或向一个特定的地方(节点)读写数据,处理流则是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写,是一种装饰器
字节到字符的转换十分耗时 非常容易出现乱码问题 这是字符流的用处
InputStreamReader 与 OutputStreamWriter 是字节流与字符流之间的桥梁
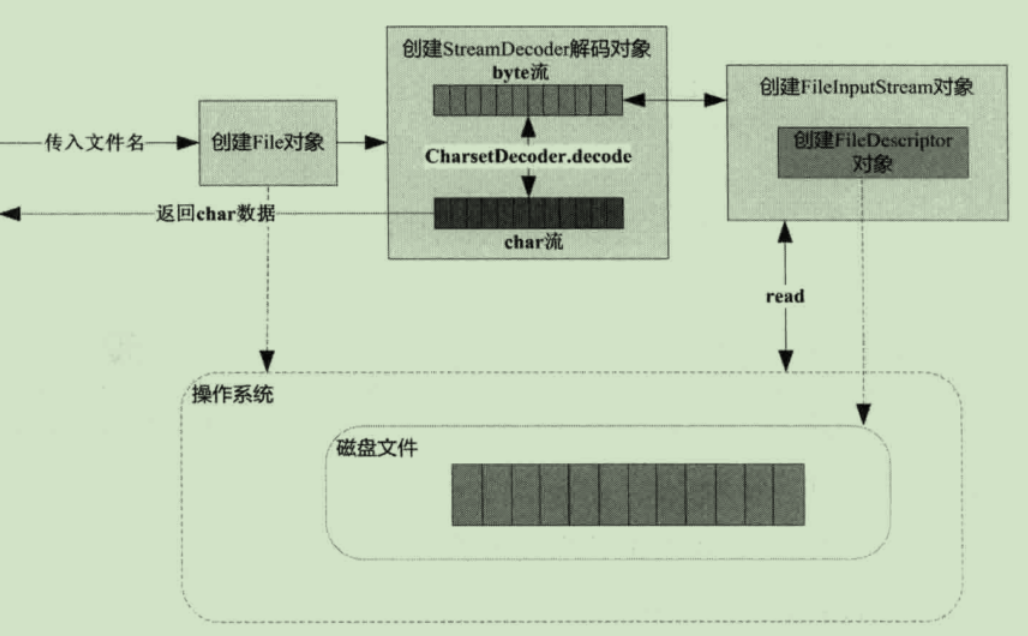
File类
File并不代表一个真实存在的真实对象
FileDescriptor才是代表一个真实文件对象
从磁盘读取文件:
构造方法
- public File(String pathname) :通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
- public File(String parent, String child) :从父路径名字符串和子路径名字符串创建新的 File实例。
- public File(File parent, String child) :从父抽象路径名和子路径名字符串创建新的 File实例
静态成员变量

获取
- public String getAbsolutePath() :返回此File的绝对路径名字符串。
- public String getPath() :将此File转换为路径名字符串。
- public String getName() :返回由此File表示的文件或目录的名称。
- public long length() :返回由此File表示的文件的长度。
判断
- public boolean exists() :此File表示的文件或目录是否实际存在。
- public boolean isDirectory() :此File表示的是否为目录。
- public boolean isFile() :此File表示的是否为文件。
创建删除
- public boolean createNewFile() :当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。
- public boolean delete() :删除由此File表示的文件或目录。
- public boolean mkdir() :创建由此File表示的目录。
- public boolean mkdirs() :创建由此File表示的目录,包括任何必需但不存在的父目录。
目录遍历
- public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。
- public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。
文件过滤器
- FileFilter
- FileNameFilter
IO
顶级父类
| 项 | 输入流 | 输出流 |
|---|---|---|
| 字节流 | 字节输入流 InputStream | 字节输出流 OutputStream |
| 字符流 | 字符输入流 Reader | 字符输出流 Writer |
字节输出流【OutputStream】
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b) :将 b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输 出到此输出流。
- public abstract void write(int b) :将指定的字节输出流。
FileOutputStream
FileOutputStream fos = new FileOutputStream("fos.txt");
for (int i =0;i<100;i++){
fos.write(("hello"+i+"\n").getBytes());
}
fos.flush();
fos.close();
- 数据追加续写
FileOutputStream fos = new FileOutputStream("fos.txt",true);
字节输入流【InputStream】
- public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
- public abstract int read() : 从输入流读取数据的下一个字节。
- public int read(byte[] b) : 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
FileInputStream
构造方法
- FileInputStream(File file) : 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
- FileInputStream(String name) : 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件 系统中的路径名 name命名。
FileInputStream fis = new FileInputStream("fos.txt");
int c = -1;
while ((c = fis.read()) != -1) {
System.out.print((char)c);
}
fis.close();
字符流
Reader
- public void close() :关闭此流并释放与此流相关联的任何系统资源。
- public int read() : 从输入流读取一个字符。
- public int read(char[] cbuf) : 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。
FileReader
FileReader reader = new FileReader("fos.txt");
int c = -1;
while ((c = reader.read()) != -1){
System.out.print((char)c);
}
Writer
- void write(int c) 写入单个字符。
- void write(char[] cbuf) 写入字符数组。
- abstract void write(char[] cbuf, int off, int len) 写入字符数组的某一部分,off数组的开始索引,len 写的字符个数。
- void write(String str) 写入字符串。
- void write(String str, int off, int len) 写入字符串的某一部分,off字符串的开始索引,len写的字符个 数。
- void flush() 刷新该流的缓冲。
- void close() 关闭此流,但要先刷新它。
FileWriter
FileWriter writer = new FileWriter("fos.txt");
writer.append("hh种");
writer.flush();
writer.close();
- flush与close的区别
JDK7中IO的异常处理
// JDK7
try (FileWriter writer = new FileWriter("fos.txt")) {
writer.append("hh种");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
// JDK9
FileWriter writer = new FileWriter("fos.txt");
try (writer) {
writer.append("hh种");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
Properties
- public Object setProperty(String key, String value) : 保存一对属性。
- public String getProperty(String key) :使用此属性列表中指定的键搜索属性值。
public Set<String> stringPropertyNames():所有键的名称的集合。
与流相关的方法
- store
- load
缓冲流
- 字节缓冲流: BufferedInputStream , BufferedOutputStream
- 字符缓冲流: BufferedReader , BufferedWriter
编码
IO 操作中的编解码
InputStreamReader reader = new InputStreamReader(new FileInputStream("gbk.txt"),"gbk");
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("utf8.txt"), StandardCharsets.UTF_8);
int c = -1;
while ((c= reader.read()) != -1){
writer.write(c);
}
writer.close();
内存编解码
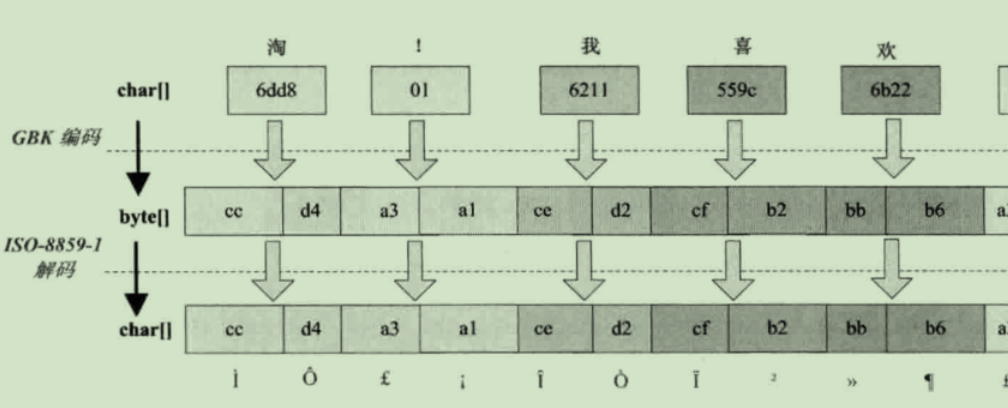
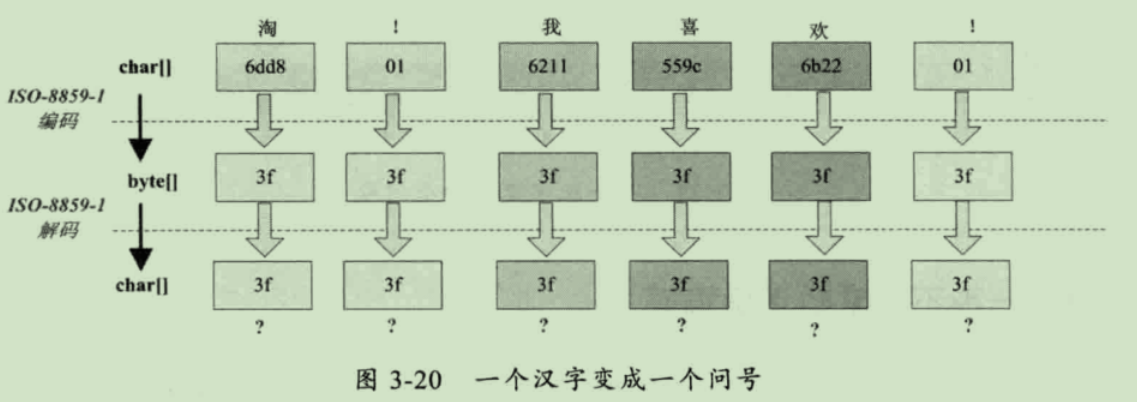
"蔡徐坤".getBytes("gbk");
new String(new byte[]{ -78, -52, -48, -20, -64, -92 },"gbk");
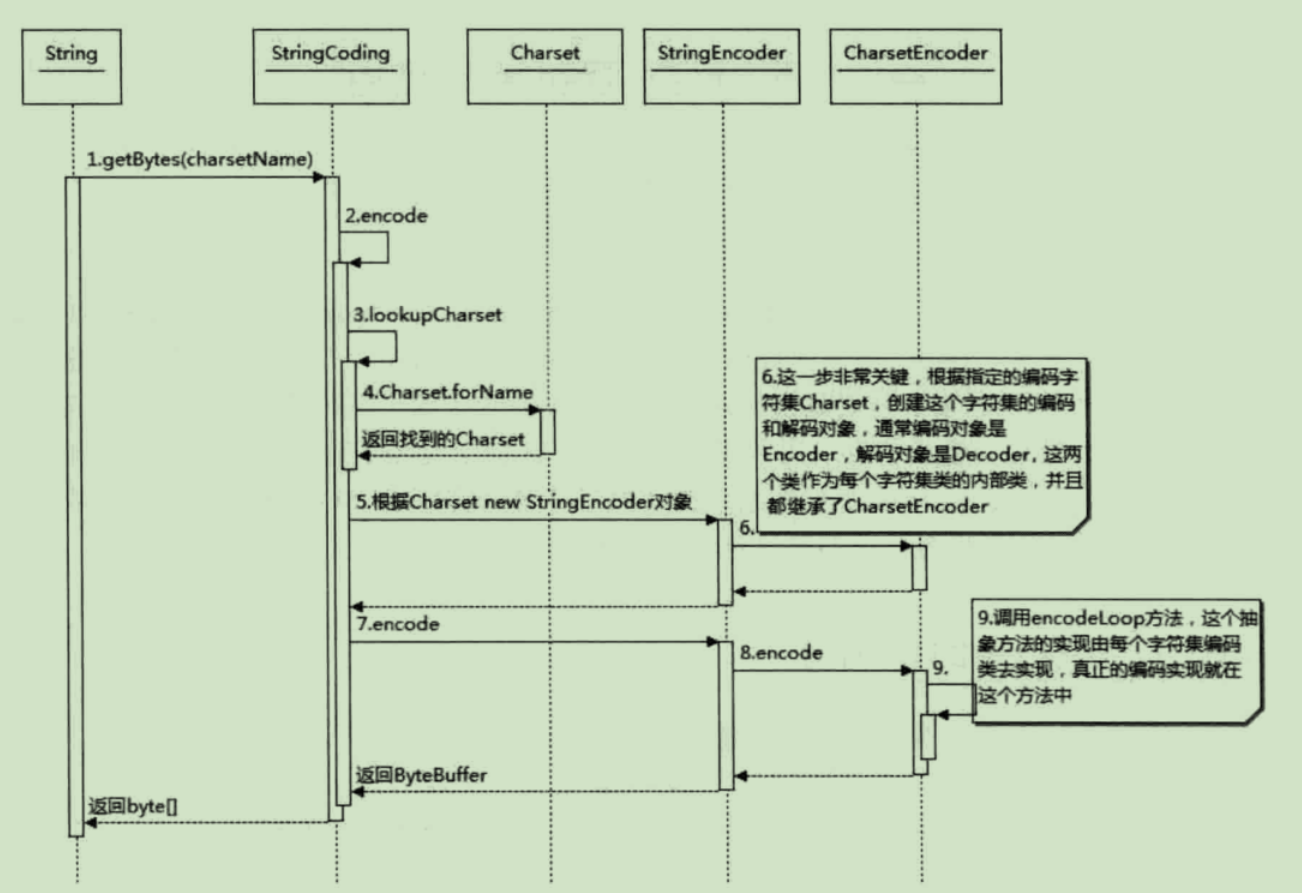
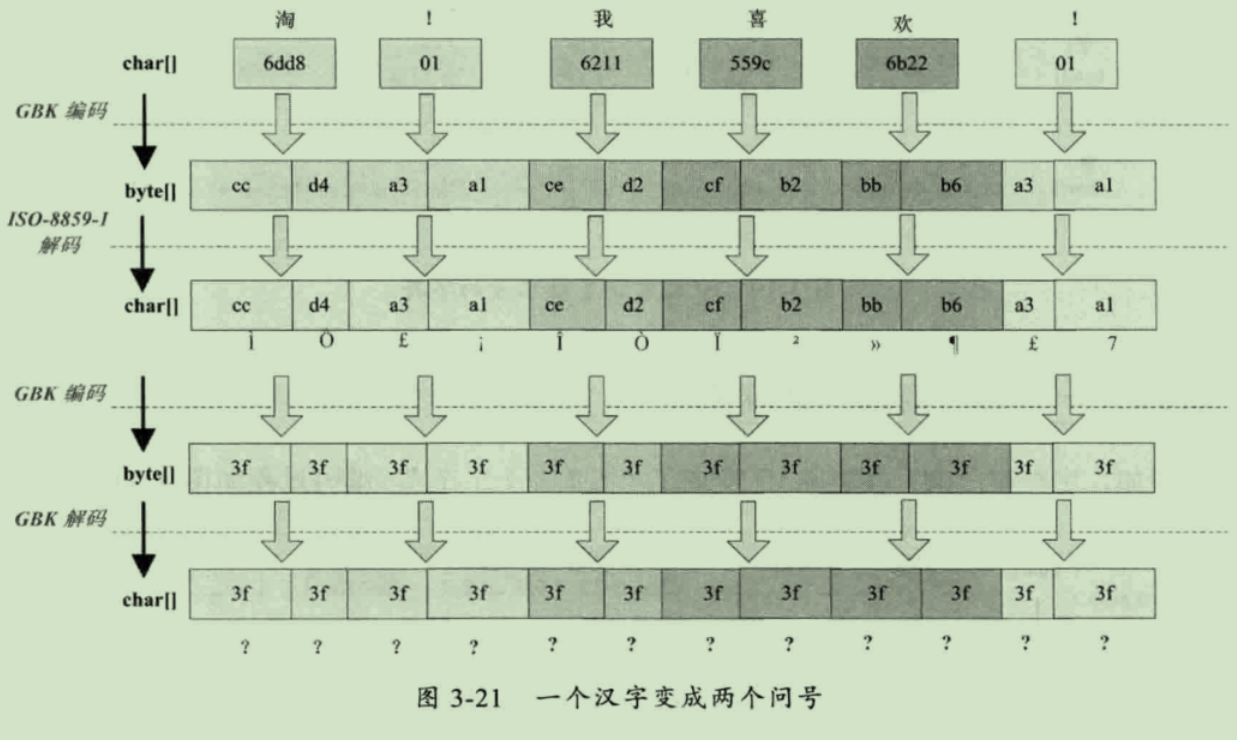
String 编码时序图:
Web 中的编解码
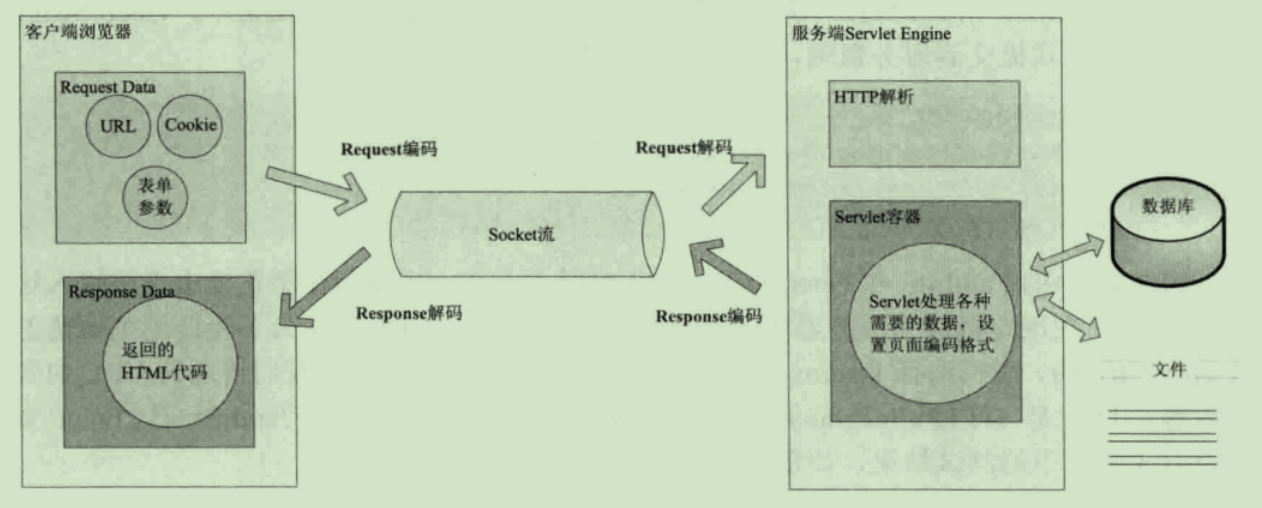
URL编解码
/页面?name=页面
这个URL被编码成%2f%e9%a1%b5%e9%9d%a2%3fname%3d%e9%a1%b5%e9%9d%a2
不同浏览器的编码可能并不一致 那么服务端是如何解析的?
tomcat中有一个配置:
<Connector URLEncoding="UTF-8">
这个配置就是用来对路径部分进行解码的
至于queryString 要不是body中的charset 要不就是ISO-8859-1
并且如果使用要body的charset的话 需要配置
<Connector useBodyEncodingForURI="true"/>
HTTP header 编解码
对于request.getHeader() 默认是使用的ISO-8859-1编码 且无法指定编码 不要再Header中传递非ASCII 字符
表单编解码
浏览器会根据ContentType的Charset对表单参数进行编码
服务端可以在Servlet容器中获取参数之前调用request.setCharacterEncoding()来指定服务器解码方式 如果没有调用此方法 那么会按照系统默认的编码方式解析
Body 编解码
服务端通过response.setCharacterEncoding来设置 这个方法的本质是设置响应头ContentType
浏览器端按照以下顺序进行解码:
- ContentType的charset
- html meta标签的charset属性
- 浏览器默认方式
js文件编码问题
如果外部引入的js文件与当前html不一致 需要
<script charset="utf8" src="xxx"></script>
常见编码问题
序列化
- ObjectOutputStream
- ObjectInputStream
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object"));
oos.writeObject(new Person("jav",15));
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object"));
Person p = (Person)ois.readObject();
序列化的类需要实现 Serializable 接口
最好手动设置 serialVersionUID 的值, 类修改时根据是否兼容来调整这个值,serialVersionUID 值不一致会抛出序列化运行时异常。
transient关键字修饰的变量不会被序列化
序列化的目的:持久化、传输
其他方式的序列化:
- Hessian 效率很高 跨语言
- Kryo 序列化
- JSON 存在的一个问题是可能存在类型丢失
序列化一些复杂对象:
- 父类继承Serializable接口 所有子类都可以序列化
- 子类实现Serializable接口 序列化后父类的属性会丢失
- 成员变量如果要被序列化 需要实现Serializable接口 否则会报错
- 反序列化时 成员如果发生修改 则发生修改的这些成员变量数据会丢失
- 如果 serialVersionUID 被修改 反序列化会失败