监控系统设计
- 为了实现可观测性
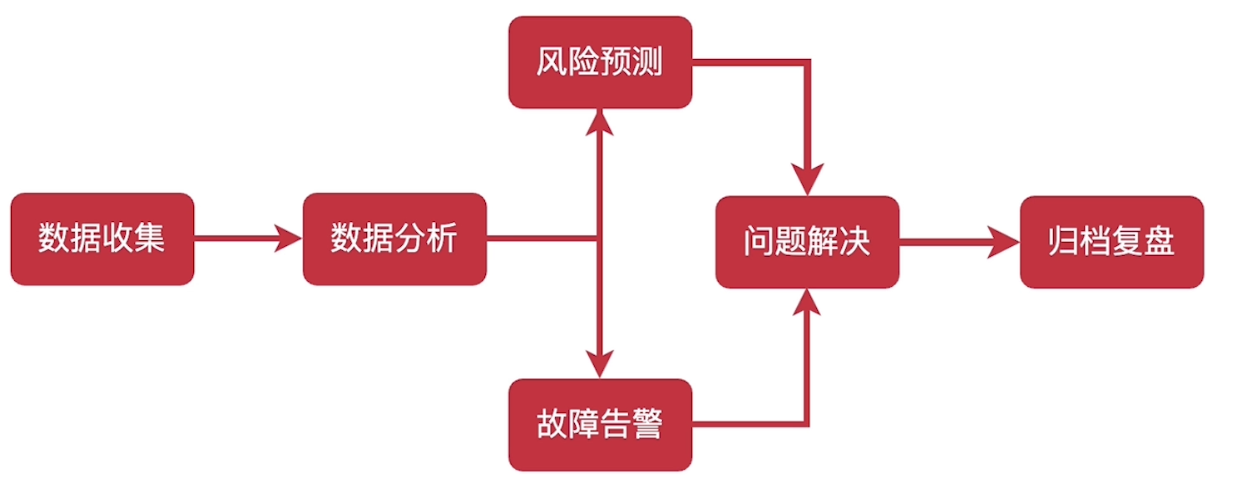
目标
- 监控指标
- 数据聚合分析
- 厉害的dashboard
- 异常检测
- 异常告警 模板与渠道
- 可扩展 高可用
监控维度
- 微服务层
- 机器层
- 中间件层
- 操作系统层
单服务单主机
主要监控主机的CPU、内存等数据以及服务所产生的日志
单服务多主机
如果所有主机都发生问题,那么可能是服务的问题
否则如果只是某一主机出现异常,问题定位就比较简单
同时,单一服务部署到多台主机,一般需要负载均衡器来分发请求,所以也要对负载均衡器进行监控
多服务多主机
此时问题定位就没那么容易了,必须收集到足够多的数据
监控范围
- 业务:指标成功率 红线 运行时异常
- 基础设施
- 流量:偏离 分布 攻击流量
- 综合性:防资损、数据巡检...
方法

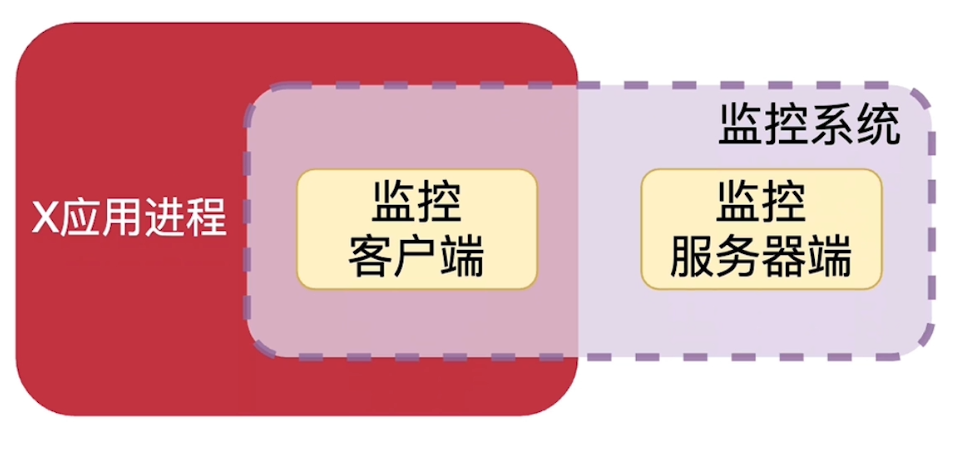
指标
黄金指标
延迟
通讯量
错误
饱和度
- 最能影响服务性能的资源
百分比指标
中位值
算数平均值
四分位数
百分25 百分50 百分75
系统指标
响应时间RT
RPS
TPS
QPS
并发用户数
业务指标
监控述求
告警渠道
告警模板
可配置性
告警分级
易用性
综合监控
通常可以对系统一些资源指标进行监控,判断实际值是否超出设定的阈值,但这些数据并不能直接说明服务是否能正常工作
语义监控
通过端到端的测试来监控服务的工作正常与否
标准化
无论是日志的格式,还是工具,都需要标准化
考虑受众
需要对日志的使用者,他们需要知道什么,想要什么以及如何消费数据等考虑清楚