查询优化
查询慢的原因
网络 CPU IO 上下文切换 系统调用 生成统计信息 锁等待
优化数据访问
查询性能低下的主要原因是访问的数据太多 需要避免检索、传输大量数据
访问了太多行和列
如果是由于访问太多行,则首先应避免写出这种SQL,MySQL会直接返回客户端所查询的全部数据,所以可以使用LIMIT来进行限制
访问了太多的列,则应该审视是否真的需要这些列,其次可以通过覆盖索引扫描的方式来进行优化。
MySQL扫描了过多的数据行
通过检查慢日志记录可以找出扫描行数过多的查询。
也可以通过EXPLAIN语句列出结果rows属性,理想情况下扫描的行和返回的行数量一致。
如果要对扫描行数与返回行数量相差较多的查询进行优化,主要可以通过
- 覆盖索引扫描的方式
- 改变表结构 使用单独的汇总表之类的
- 重写掉这个复杂的查询
重构查询
对于一些操作数据量大的SQL,如果可以将其拆分成几个小SQL,在应用层进行处理,那可以把服务器的压力分摊到各个时间点中。
如可以对一些关联查询进行分解:
- 可以利用缓存
- 降低锁争用
- 应用层处理拥有较高的可扩展性
- ...
查询执行
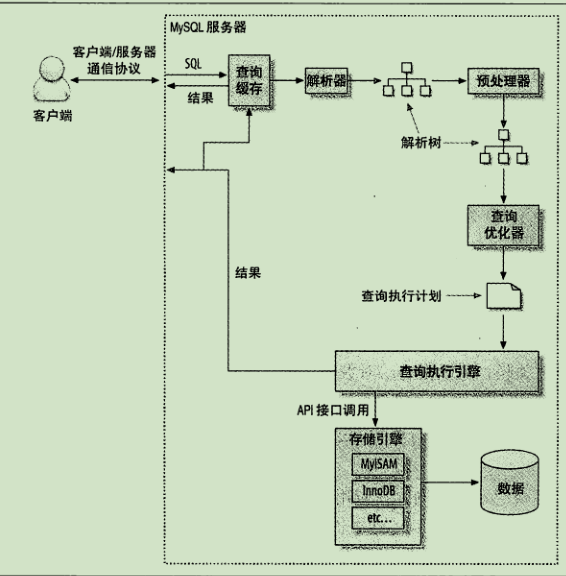
一条查询SQL的执行流程:
- 先进行缓存查询,如果命中缓存,则直接返回,否则继续
- 接下来会对SQL进行解析与处理,将SQL转为AST,语法错误在这个阶段被发现
- 接下来走到优化器,这个阶段会根据策略找到MySQL认为最优的执行方式
- 最后走到执行引擎这里,有大量的操作需要通过调用存储引擎实现的接口来完成,如调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中,慢查询日志有个rows_examined字段,表示了在执行这条SQL语句时,MySQL扫描了多少行数据
被废弃的查询缓存
从5.6开始 MySQL就禁用了缓存 8.0更是废弃了缓存
- 当缓存靠近客户时,缓存会带来最大的好处
通信协议
MySQL的数据传输是半双工,一方发送完数据包后,必须等待对方回应才能进行下一步操作。通过设置max_allowed_packet参数来限制数据包大小
每个MySQL连接都有类似于线程的状态,通过这些状态可以发现一些不正常的连接:
SHOW FULL PROCESSLIST
Sleep、Query、Locked... 参考general-thread-states
查询优化处理
sql -> 语法树 -> 查询优化器 -> 选择优化器认为最佳的执行计划 -> 执行
由于种种原因,优化器最后可能会选择错误的执行计划
优化器计算的依据
- 每个表或者索引的页面个数
- 索引的基数
- 索引和数据行的长度
- 索引的分布情况
优化策略
- 静态优化 直接对解析树进行分析,并完成优化 只需执行一次
- 动态优化 动态优化与查询的上下文有关,也可能跟取值、索引对应的行数有关 每次优化都得重新执行
优化类型
- 重新定义关联表的顺序
- 将外连接转化成内连接,内连接的效率要高于外连接
- 使用等价变换规则,mysql可以使用一些等价变化来简化并规范表达式(1=1 and a > b => a> b)
- 优化count(),min(),max() min和max可以通过读取B树索引的第一条记录和最后一条记录实现
- 这种优化使用EXPLAIN解释会出现
Select tables optimized away
- 这种优化使用EXPLAIN解释会出现
- 预估并转化为常数表达式,当mysql检测到一个表达式可以转化为常数的时候,就会一直把该表达式作为常数进行处理
- 索引覆盖扫描,当索引中的列包含所有查询中需要使用的列的时候,可以使用覆盖索引
- 子查询优化
- 提取终止查询 如limit子句或者不可能的where条件
- 等值传播 将同样适合其他表的where条件也应用到其他表上
- IN() 会进行排序 使用二分查找
关联查询执行
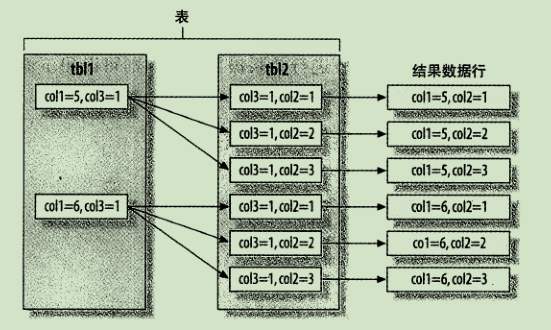
排序优化
当排序的数据量过大,则会在文件中进行排序(filesort),使用两次传输排序或者单次传输排序,排序时消耗的临时磁盘空间要比排序的数据本身大得多。所以尽量使用LIMIT子句来降低需要排序的数据量。
MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer,排序过程是否在内存中完成,取决于排序所需的内存和参数 sort_buffer_size,sort_buffer_size 越小,需要分成的份数越多,也就需要更多的临时文件
全字段排序(单次传输排序):
- 初始化 sort_buffer,放入 select 指定的字段
- 不断找出满足记录的数据,取出 select 指定的字段放入 sort_buffer
- 对 sort_buffer 中的数据按照排序字段排序
max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,就改用两次传输排序
rowid 排序(两次传输排序):
- 初始化 sort_buffer
- 找出满足记录的数据的主键,根据主键再回表查到所需要的字段
- 对 sort_buffer 中的数据按照排序字段排序
并不是所有的 order by 子句都需要进行排序,如果索引合适,MySQL 可以直接利用索引的有序性直接得到有序结果,甚至还不用回表:
-- 如果在这张表上有个联合索引(city,name)
SELECT city,name FROM person WHERE city = '厦门' ORDER BY name
order by rand():这个语句需要 Using temporary 和 Using filesort,查询的执行代价往往是比较大的,内存临时表排序的时候使用了 rowid 排序方法
- 创建一个临时表,除了 select 的字段之外,还有一个一个随机值
- 按照随机值排序
tmp_table_size 这个配置限制了内存临时表的大小,默认值是 16M。如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表
优化器的局限
- 老版本IN子查询的性能缺陷
- 有时无法将外层限制条件下推到内层(外层查询的条件作用到内层查询)
- IN等值传递问题
- 8.0之前对于一个SQL语句,MySQL最多只能使用一个CPU核来处理
- 8.0后通过
innodb_parallel_read_threads来指定并发数
- 8.0后通过
给优化器提示
通过给SQL语句加上一些标志,比如常见的INSERT DELAYED,来明确控制优化器的行为
若非必要,不要使用这些提示,每次MySQL新版本都会加入许多优化策略,这些提示可能会造成优化策略失效
https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html
优化特定类型查询
count 查询
COUNT(列或表达式) 计算的是列或表达式有值(非NULL)的数量,而COUNT(*) 计算的就是结果集数。
- 在MyISAM中,只有没有任何where条件的count(*)才是比较快的
- 不需要完全精确的值,可以参考使用近似值来代替,比如可以使用explain来获取近似的值
- 增加汇总表,或者增加外部缓存系统来缓存计数
- 使用二级索引扫描的数据量比使用聚簇索引扫描的数据量少,因为二级索引的叶子结点存储的是主键
count(主键 id):遍历整张表,把每一行的 id 值都取出来拿到 id 后,判断是不可能为空的,就按行累加
count(1):遍历整张表,但不取值,对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加
count(字段):对于有可能是 null的,还要把值取出来再判断一下,不是 null 才累加
count(*):是例外,专门做了优化,不取值。这个count返回的每一行肯定不是 null,按行累加
按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*)
关联查询
- 确保on或者using子句中的列上有索引
- 确保任何的groupby和order by中只涉及到一个表中的列, 这样可以有效利用索引排序
子查询优化
- 5.6之前的可使用关联查询替代,5.6之后不用考虑这个问题
limit 分页大偏移量优化
- 优化此类查询的最简单的办法就是尽可能地使用覆盖索引,而不是查询所有的列 然后使用关联查询 查询出具体值
SELECT * FROM xx
INNER JOIN(SELECT id FROM xx LIMIT 999,5)
- 另外一种方式是计算出当前偏移量之前的某个具体值 然后使用where条件过滤掉偏移量之前的数据
SELECT * FROM xx WHERE id > 1000 LIMIT 5
- 对于大量分页,使用下一页来替代掉具体页码的分页,通过每次查询出比数量多一条的数据,来判断有没有下一页
优化union查询
除非确实需要服务器消除重复的行,否则一定要使用union all
使用用户自定义变量
SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;
SELECT @last_week;
使用限制:无法使用查询缓存、变量的生存域在连接中
使用索引
索引的原理:
MySQL 使用索引的方式:
- WHERE ORDER BY GROUP PY子句
- 对于使用MIN MAX函数的查询直接使用索引就可完成
- 对于某些查询 只使用索引的数据就可返回 无需回表查询
索引的代价:
- 降低了大部分写操作的速度
- 占用磁盘空间
挑选索引:
- 用于搜索 排序 分组的列
- 列的基数(列的值不重复的个数)越高 索引效果越好
- 索引尽量选择较小的数据类型
- IO 操作更快
- 降低存储空间需求 可以在缓存中缓存更多数据 加快速度
- 字符串索引指定前缀长度
- 大多数字符串前n个字符就足以是唯一的 当成索引
- 最左索引
- 对于(a,b,c)这种类型的复合索引 利用其排列顺序进行操作 能有效利用索引
- 不要过多的索引
- 保持参与比较的索引类型匹配
- 散列 B+树
查询优化程序
EXPLAIN SELECT * FROM person WHERE FALSE
有助于优化程序对索引充分利用:
- 分析表
ANALYZE TABLE- 生成键值分析
- 当 MySQL 由于统计信息错误选择了错误的执行计划,也可以用这个命令
- 使用 EXPLAIN 验证哪些索引会被使用到
- 必要时给予 EXPLAIN提示
- 表名后面加上
FORE INDEX, USE INDEX, IGNORE INDEX STRAIGHT_JOIN要求按特定顺序使用表
- 表名后面加上
- 比较的列数据类型相同
- 索引列不要参与运算
- LIKE 语句开始位置不要使用通配符
- 将子查询转换为连接
- 尝试查收的各种替代形式
- 避免过多类型的自动转换
数据类型高效查询
- 多用数字运算 少用字符串运算
- ENUM SET
- 优先使用较小数据类型
- 加快操作速度
- 节省存储空间
- 数据列声明NOT NULL
- 避免 MySQL 运行时检查 NULL
- 考虑使用ENUM
- 输出MySQL对数据类型的建议
SELECT * FROM tb PROCEDURE ANALYSE()
- 整理表碎片
OPTIMIZE TABLE tb- 某些存储引擎不支持 使用mysqldump导出再导入来整理
- 使用BLOB TEXT存储非结构化数据
- 注意删除更新时留下的碎片
- 避免过大
- 抽离到一张独立的表
- 合成索引
- 计算一个散列值存放到一个列
表存储格式高效查询
MyISAM:
- 默认使用固定长度的行
- 当某个列长度可变时 则行也会变成可变
- 固定长度的行比变长行处理速度比较快
MEMORY:
- 使用都是固定长度的行
InnoDB:
- 默认情况是COMPACT行格式
- 对于包含重复数据表 使用 COMPRESSED航格式 占用空间较少
- 带有TEXT 或 BLOB 使用 DYNAMIC
CREATE TABLE tb (...) ROW_FORMAT = xxx;
高效加载数据
- LOAD DATA 比 INSERT 效率更高
- 数据加载时磁盘IO操作越少 效率越高
调度 锁定 并发
调度策略:
- 写入优先级比读取优先级高
- 写入操作一次只能执行一个 写入操作时公平的
- 可以同时处理多个对同一个表的读取
InnoDB: 行级锁 更精细 并发度更高
MyISAM: 表级锁 不会出现死锁问题