内核
系统调用
进程管理相关
- fork:创建一个子进程
- execve:运行另外一个指定的程序。 它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃
- waitpid:父进程可以调用它,将子进程的进程号作为参数传给它,这样父进程就知道子进程运行结果
内存管理相关
- brk:会和原来的堆的数据连在一起
- mmap:申请一块新内存区域
文件管理相关
- open close
- creat
- lseek
- read write
信号处理相关
对于一些不严重的信号,可以忽略,该干啥干啥,但是像 SIGKILL(用于终止一个进程的信号)和 SIGSTOP(用于中止一个进程的信号)是不能忽略的,每种信号都定义了默认的动作
- kill:可以向某个进程发送一个杀掉的信号
- sigaction:注册一个信号处理函数
进程间通信相关
- msgget:创建一个新的队列
- msgsnd:将消息发送到消息队列
- msgrcv:从队列中取消息
- shmget:创建一个共享内存块
- shmat:将共享内存映射到自己的内存空间
- sem_wait:获取或者等待获取信号量(已经被人获取的情况下)
- sem_post:释放信号量
Glibc
除了封装了丰富的API,最重要的是封装了操作系统提供的系统服务,即系统调用的封装
初始化
BIOS到bootloader
电脑刚加电的时候,会做一些重置的工作,将 CS 设置为 0xFFFF,将 IP 设置为 0x0000,所以第一条指令就会指向 0xFFFF0,正是在 ROM 的范围内。在这里,有一个 JMP 命令会跳到 ROM 中做初始化工作的代码,于是,BIOS 开始进行初始化的工作
启动盘一般在第一个扇区,占 512 字节,而且以 0xAA55 结束。这是一个约定,当满足这个条件的时候,就说明这是一个启动盘,在 512 字节以内会启动相关的代码
Linux 里面有一个工具,叫 Grub2,就可以对启动盘的这个代码进行配置
menuentry 'CentOS Linux (3.10.0-862.el7.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-862.el7.x86_64-advanced-b1aceb95-6b9e-464a-a589-bed66220ebee' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' b1aceb95-6b9e-464a-a589-bed66220ebee
else
search --no-floppy --fs-uuid --set=root b1aceb95-6b9e-464a-a589-bed66220ebee
fi
linux16 /boot/vmlinuz-3.10.0-862.el7.x86_64 root=UUID=b1aceb95-6b9e-464a-a589-bed66220ebee ro console=tty0 console=ttyS0,115200 crashkernel=auto net.ifnames=0 biosdevname=0 rhgb quiet
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img
}
grub2 第一个要安装的就是 boot.img。它由 boot.S 编译而成,一共 512 字节,正式安装到启动盘的第一个扇区,然后再加载core.img,core.img由 lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做很多事情
boot.img 先加载的是 core.img 的第一个扇区。如果从硬盘启动的话,这个扇区里面是 diskboot.img,diskboot.img 的任务就是将 core.img 的其他部分加载进来,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img
在真正的解压缩之前,lzma_decompress.img 做了一个重要的决定,就是调用 real_to_prot,切换到保护模式:
- 启用分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了
- 启动分页
kernel.img 对应的代码是 startup.S 以及一堆 c 文件,在 startup.S 中会调用 grub_main,这是 grub kernel 的主函数,grub_load_config() 开始解析配置文件,最后会调用 grub_command_execute (“normal”, 0, 0)进行选择操作系统
一旦,选定了某个操作系统,启动某个操作系统,就要开始调用 grub_menu_execute_entry(),然后启动内核
内核初始化
内核的初始化过程,主要做了以下几件事情:
- 各个内核模块的创建
- 用户态祖先进程的创建
- 内核态祖先进程的创建
- 初始化0号进程:INIT_TASK(init_task)
- trap_init():设置了很多中断门(Interrupt Gate),用于处理各种中断
- mm_init():初始化内存管理模块
- ched_init(): 初始化调度模块
- 初始化1号进程:kernel_thread(kernel_init, NULL, CLONE_FS)
- 它会尝试运行 ramdisk 的“/init”,从内核态进入到用户态,用来管理用户态进程
- 初始化2号进程:kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES),用来管理内核态进程
系统调用的执行
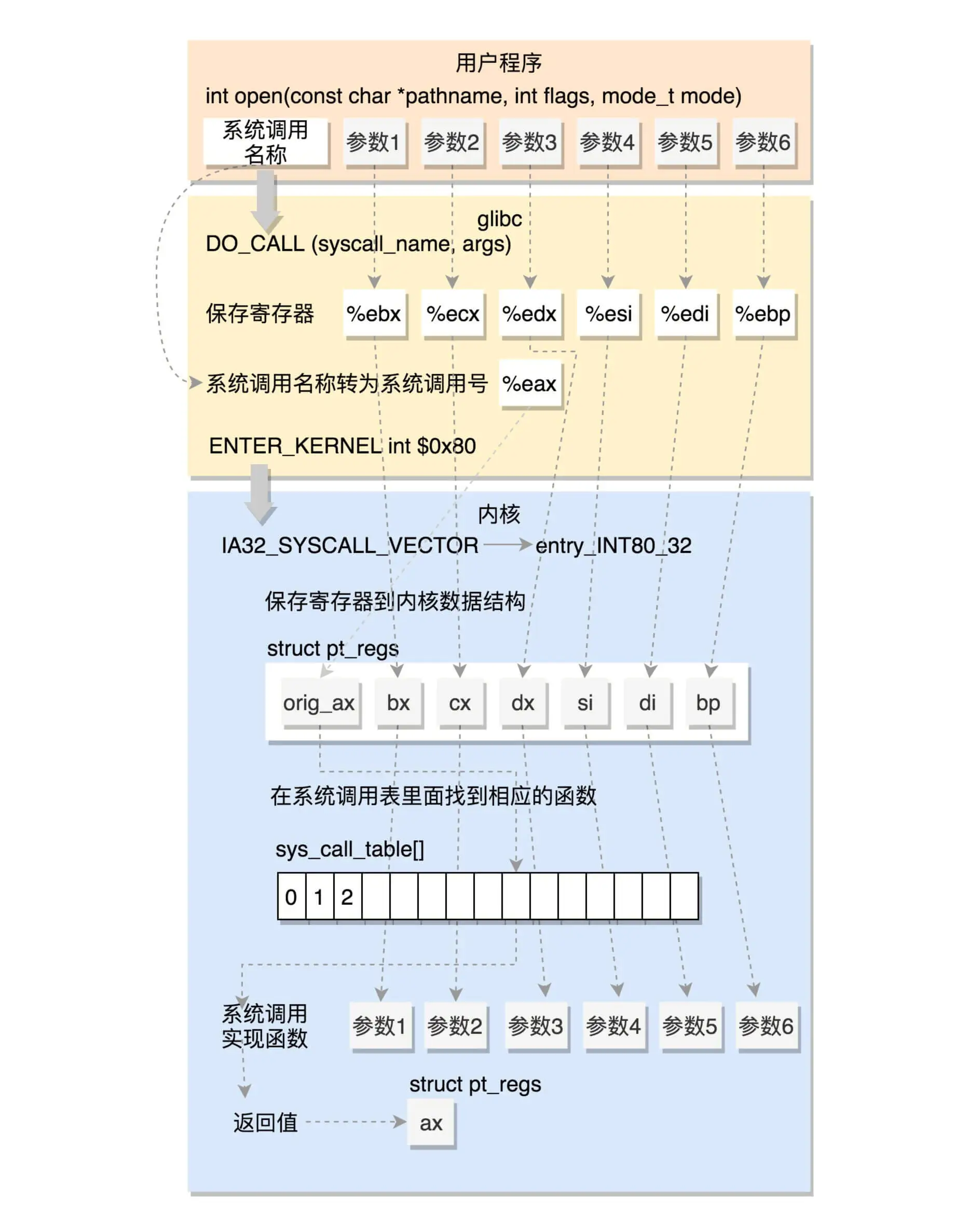
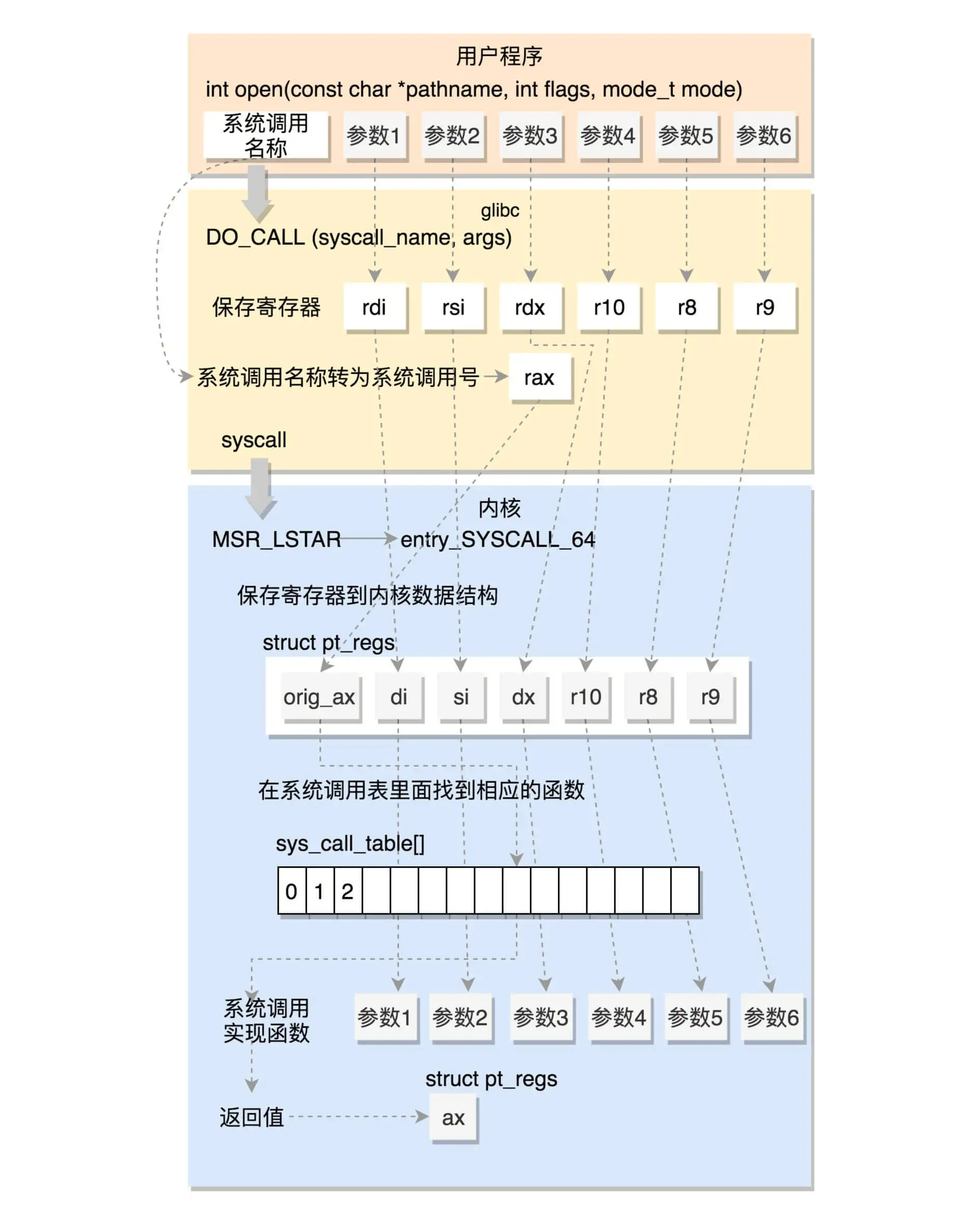
系统调用表
# 32位系统调用表
5 i386 open sys_open compat_sys_open
# 64位系统调用表
2 common open sys_open
- 第一列的数字是系统调用号
- 第三列是系统调用的名字
- 第四列是系统调用在内核的实现函数
// 系统调用声明
asmlinkage long sys_open(const char __user *filename,
int flags, umode_t mode);
系统调用实现本质就是通过一些宏定义,再根据上述的声明,在编译时进行生成
进程管理
加载程序到进程
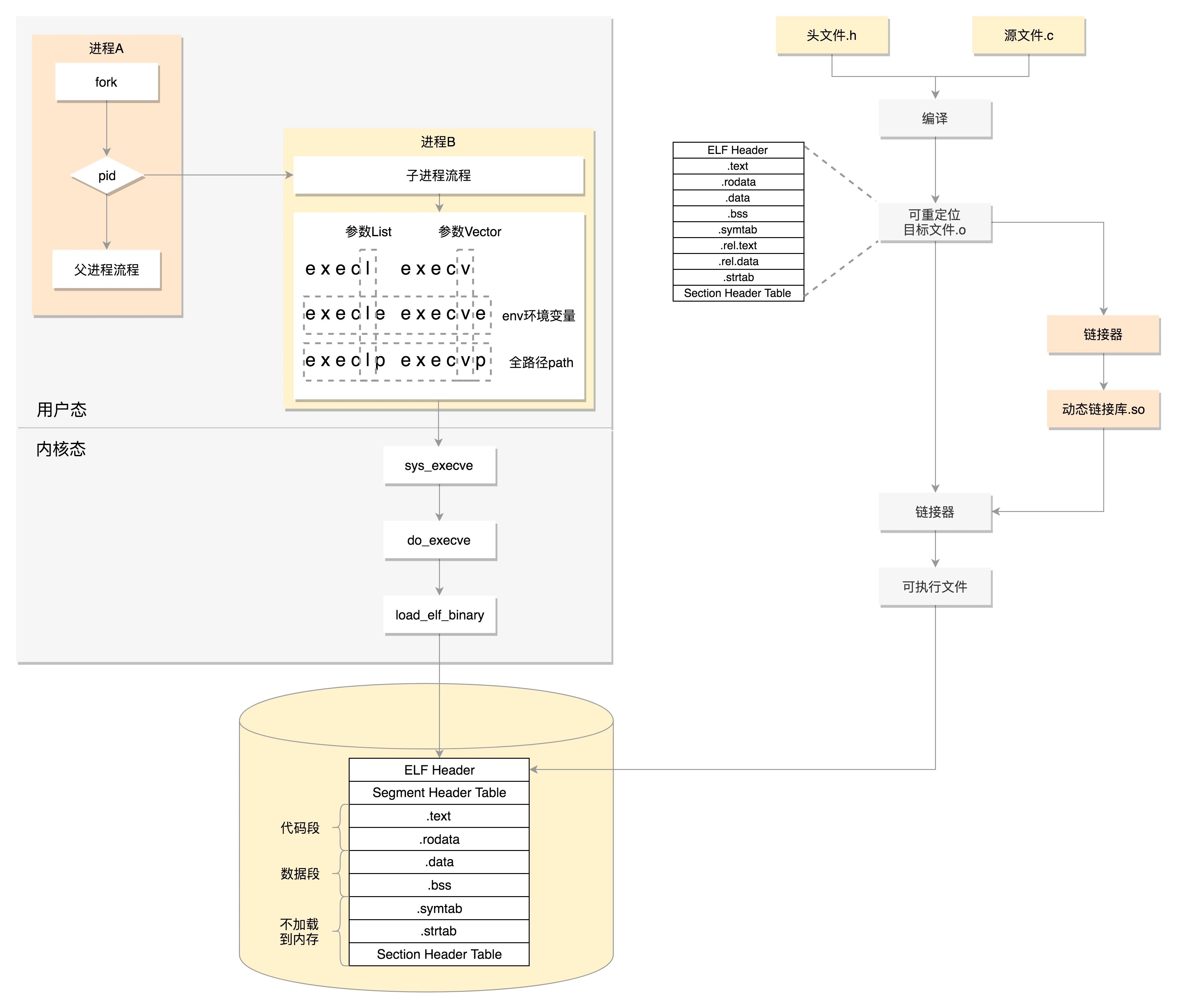
进程数据结构
任务ID
pid_t pid; // 进程的id
pid_t tgid; // 线程组id
struct task_struct *group_leader; // 主线程
信号处理
struct signal_struct *signal;
struct sighand_struct *sighand; // 哪些信号正在通过信号处理函数进行处理
sigset_t blocked; // 哪些信号被阻塞暂不处理
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending; // 哪些信号尚等待处理
/* 信号处理函数默认使用用户态的函数栈,这三个变量就是用来记录栈的状态 */
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
任务状态
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
int exit_state;
unsigned int flags;
/* 状态的取值 */
/* Used in tsk->state: */
#define TASK_RUNNING 0 // 表示进程在时刻准备运行的状态。当处于这个状态的进程获得时间片的时候,就是在运行中
#define TASK_INTERRUPTIBLE 1 // 可中断的睡眠状态,可以响应信号
#define TASK_UNINTERRUPTIBLE 2 // 不可中断的睡眠状态,即使kill信号也无法响应
#define __TASK_STOPPED 4 // 接收到 SIGSTOP、SIGTTIN、SIGTSTP 或者 SIGTTOU 信号之后进入该状态
#define __TASK_TRACED 8 // 进程被 debugger 等进程监视,进程执行被调试程序所停止
/* Used in tsk->exit_state: */
#define EXIT_DEAD 16 // 进程的最终状态
#define EXIT_ZOMBIE 32 // 当进程exit()退出之后,他的父进程没有通过wait()系统调用回收他的进程描述符的信息,该进程会继续停留在系统的进程表中
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_NEW 2048
#define TASK_STATE_MAX 4096
flags:
#define PF_EXITING 0x00000004 // 表示正在退出
#define PF_VCPU 0x00000010 // 运行在虚拟 CPU 上
#define PF_FORKNOEXEC 0x00000040 // fork 完了,还没有 exec
进程调度
//是否在运行队列上
int on_rq;
//优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
//调度器类
const struct sched_class *sched_class;
//调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
//调度策略
unsigned int policy;
//可以使用哪些CPU
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info;
运行统计信息
u64 utime;//用户态消耗的CPU时间
u64 stime;//内核态消耗的CPU时间
unsigned long nvcsw;//自愿(voluntary)上下文切换计数
unsigned long nivcsw;//非自愿(involuntary)上下文切换计数
u64 start_time;//进程启动时间,不包含睡眠时间
u64 real_start_time;//进程启动时间,包含睡眠时间
进程亲缘关系
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
大部分情况下,real_parent 和 parent 是一样的
如果在 bash 上使用 GDB 来 debug 一个进程,这个时候 GDB 是 parent,bash 是这个进程的 real_parent
进程权限
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
- real_cred 就是说明谁能操作我这个进程
- cred 就是说明我这个进程能够操作谁
struct cred {
......
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
......
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
......
} __randomize_layout;
- uid 和 gid:一般情况下,谁启动的进程,就是谁的 ID
- euid 和 egid:实际用来判断是否有权限就是通过这两个
- fsuid 和 fsgid:对文件操作时用来审核的标志
- cap_permitted:表示进程能够使用的权限
- cap_inheritable: 表示当可执行文件的扩展属性设置了 inheritable 位时,调用 exec 执行该程序会继承调用者的 inheritable 集合
- cap_bset:统中所有进程允许保留的权限。如果这个集合中不存在某个权限,那么系统中的所有进程都没有这个权限
- cap_ambient:非 root 用户进程使用 exec 执行一个程序的时候,如何保留权限的问题。当执行 exec 的时候,cap_ambient 会被添加到 cap_permitted 中,同时设置到 cap_effective 中
函数调用
struct thread_info thread_info;
void *stack;
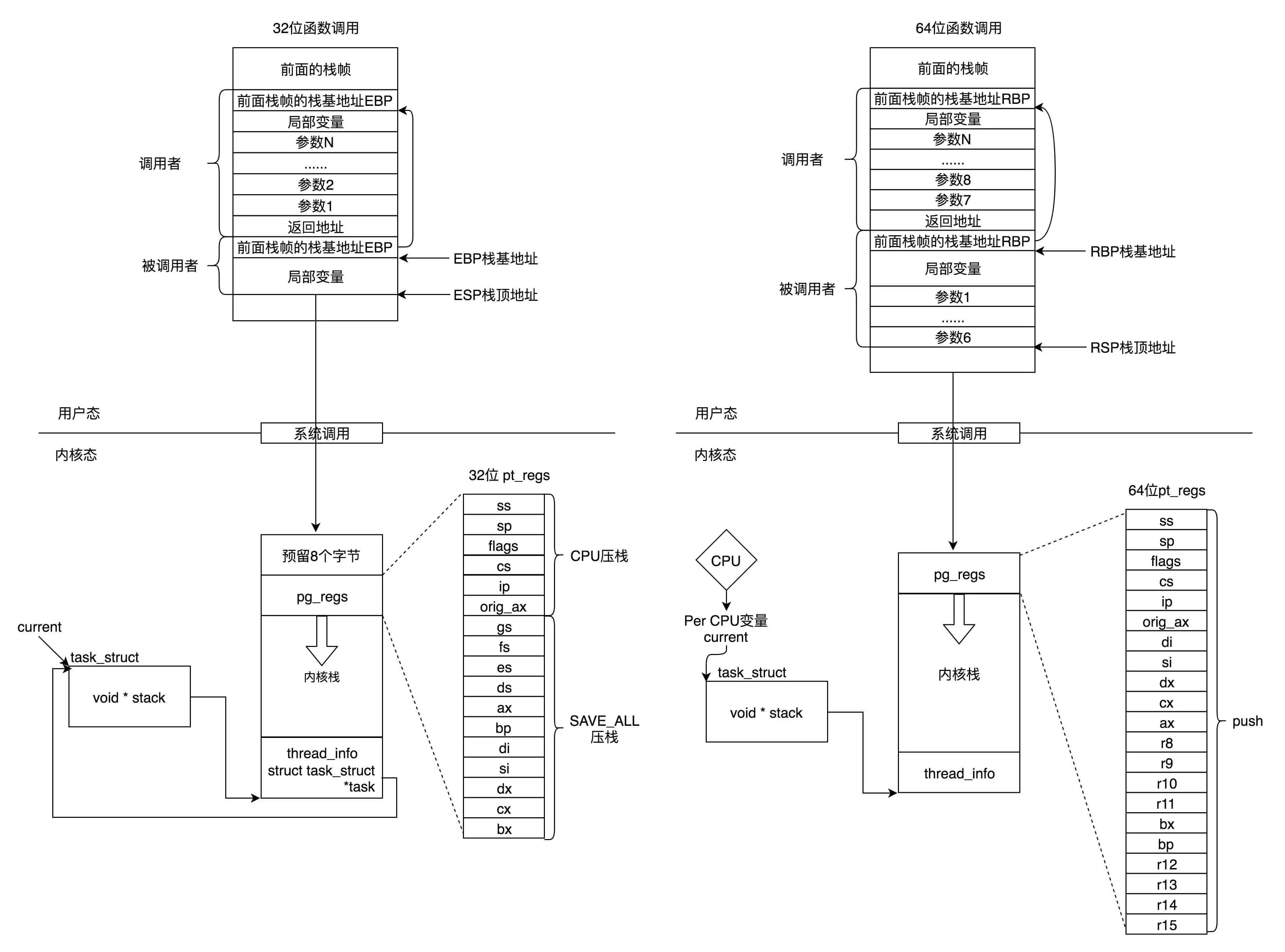
对于32位:
- ESP(Extended Stack Pointer)是栈顶指针寄存器
- EBP(Extended Base Pointer)是栈基地址指针寄存器,指向当前栈帧的最底部
对于64位:
- rax 用于保存函数调用的返回结果。
- 栈顶指针寄存器变成了 rsp,指向栈顶位置。堆栈的 Pop 和 Push 操作会自动调整 rsp
- 栈基指针寄存器变成了 rbp
参数传递用到了 rdi、rsi、rdx、rcx、r8、r9 这 6 个寄存器,用于传递存储函数调用时的 6 个参数。如果超过 6 的时候,还是需要放到栈里面
每个线程都会分配一个内核栈,分配的内核栈是8k(32位),16k(64位)
当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的 CPU 上下文保存起来,其实主要就是保存在这个结构的寄存器变量里。这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去
在内核态,32 位和 64 位的内核栈和 task_struct 的关联关系不同。32 位主要靠 thread_info,64 位主要靠 Per-CPU 变量
调度
unsigned int policy; // 调度策略
/* 优先级 */
int prio, static_prio, normal_prio;
unsigned int rt_priority;
调度策略
/* 相同条件小,优先级高的总是可以抢占优先级低的 */
#define SCHED_NORMAL 0
#define SCHED_FIFO 1 // 实时:先入先出
#define SCHED_RR 2 // 实时:轮询
#define SCHED_BATCH 3 // 普通:后端批处理、不用交互的进程
#define SCHED_IDLE 5 // 普通:特别空闲的时候才跑的进程
#define SCHED_DEADLINE 6 // 实时:调度器总是选择其 deadline 距离当前时间点最近的那个任务
完全公平调度算法
在普通调度中使用,随着时间片轮转,每次都会选中一个进程,每个被选中的进程自身的vruntime就增大,辅之以权重,每次挑选vruntime最小的进程进行调度以达到公平的目的
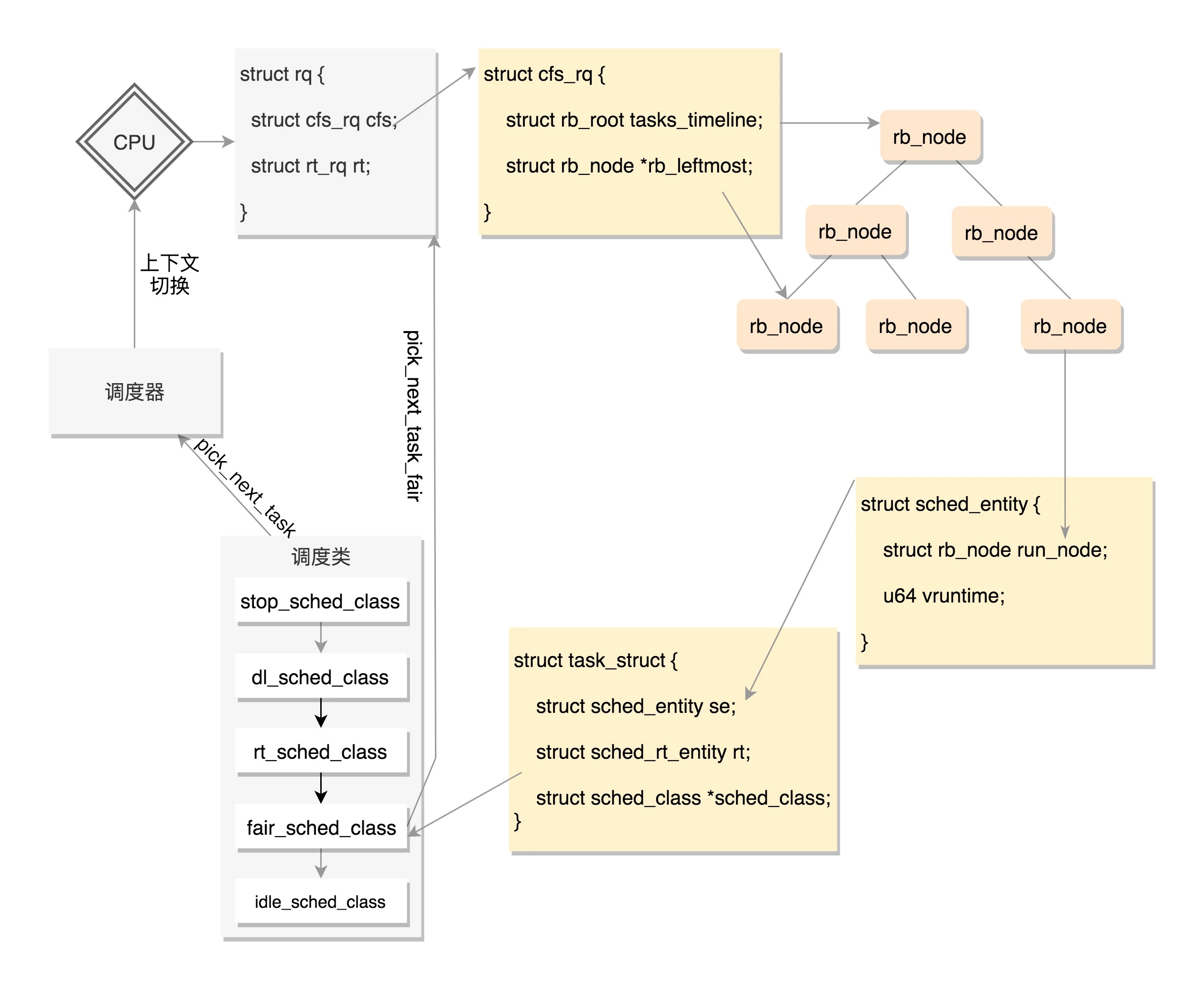
调度实体与调度队列
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
......
};
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct sched_entity *curr, *next, *last, *skip;
......
};
每个 CPU 都有自己的 struct rq 结构,其用于描述在此 CPU 上所运行的所有进程,其包括一个实时进程队列 rt_rq 和一个 CFS 运行队列 cfs_rq,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去 CFS 运行队列找是否有进程需要运行,内核会在每一个时钟周期末尾触发rebalance,这样可以进行各个CPU的任务再均衡,同时每个CPU如果发现自己队列空了,会进行任务窃取,执行别的CPU的任务
调度器操作
- enqueue_task 向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数
- dequeue_task 将一个进程从就绪队列中删除
- pick_next_task 选择接下来要运行的进程
- put_prev_task 用另一个进程代替当前运行的进程
- set_curr_task 用于修改调度策略
- task_tick 每次周期性时钟到的时候,这个函数被调用,可能触发调度
主动调度
- 协作式,进程在执行某些操作时,发现需要进行等待,就主动让出CPU,选择调用 schedule() 函数
static ssize_t tap_do_read(struct tap_queue *q,
struct iov_iter *to,
int noblock, struct sk_buff *skb)
{
......
while (1) {
if (!noblock)
prepare_to_wait(sk_sleep(&q->sk), &wait,
TASK_INTERRUPTIBLE);
......
/* Nothing to read, let's sleep */
schedule();
}
......
}
调度过程:
挑选一个任务,如果该任务不是当前任务,则准备上下文切换,上下文所做的事就是保存内核栈的栈顶指针、寄存器到TSS里面
抢占式调度
- 场景一:一个进程执行时间太长了,是时候切换到另一个进程了,在时钟中断的时候,进程陷入内核态,返回的时候触发抢占
- 场景二:当一个进程被唤醒的时候,当被唤醒的进程优先级高于 CPU 上的当前进程,就会触发抢占
当发现当前进程应该被抢占,即运行的时间够多了,会将这个进程打上一个标签 TIF_NEED_RESCHED,等待它调用__schedule时重新进行调度
抢占时机:
- 对于用户态的进程:
- 从系统调用中返回的那个时刻
- 从中断中返回的那个时刻
- 对于内核态的进程:
- preempt enable调用__ schedule
- do_ IRQ后retint_ kernel调用__ schedule
进程创建
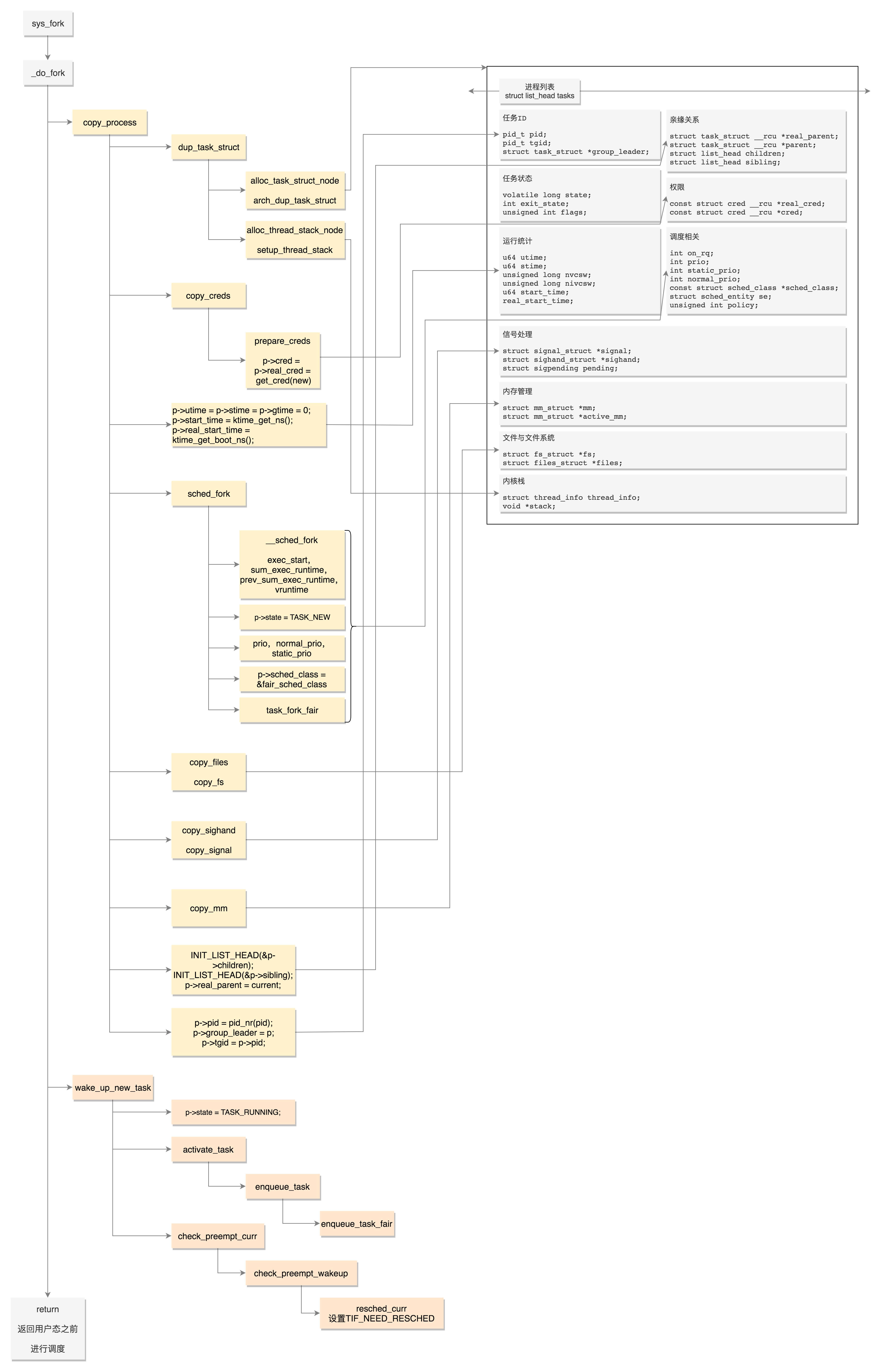
- copy_process
- dup_task_struct:复制线程的结构
- copy_creds复制权限
- sched_fork:设置调度相关的变量
- copy_files:复制进程打开的文件信息
- copy_fs:复制进程的目录信息
- copy_sighand:维护信号处理函数
- copy_mm:复制进程内存空间
- 分配 pid,设置 tid,group_leader,并且建立进程之间的亲缘关系
- wake_up_new_task
- 将进程的状态设置为 TASK_RUNNING
- 将进程加入任务队列
- 更新运行的统计量
- 调度
线程创建与使用
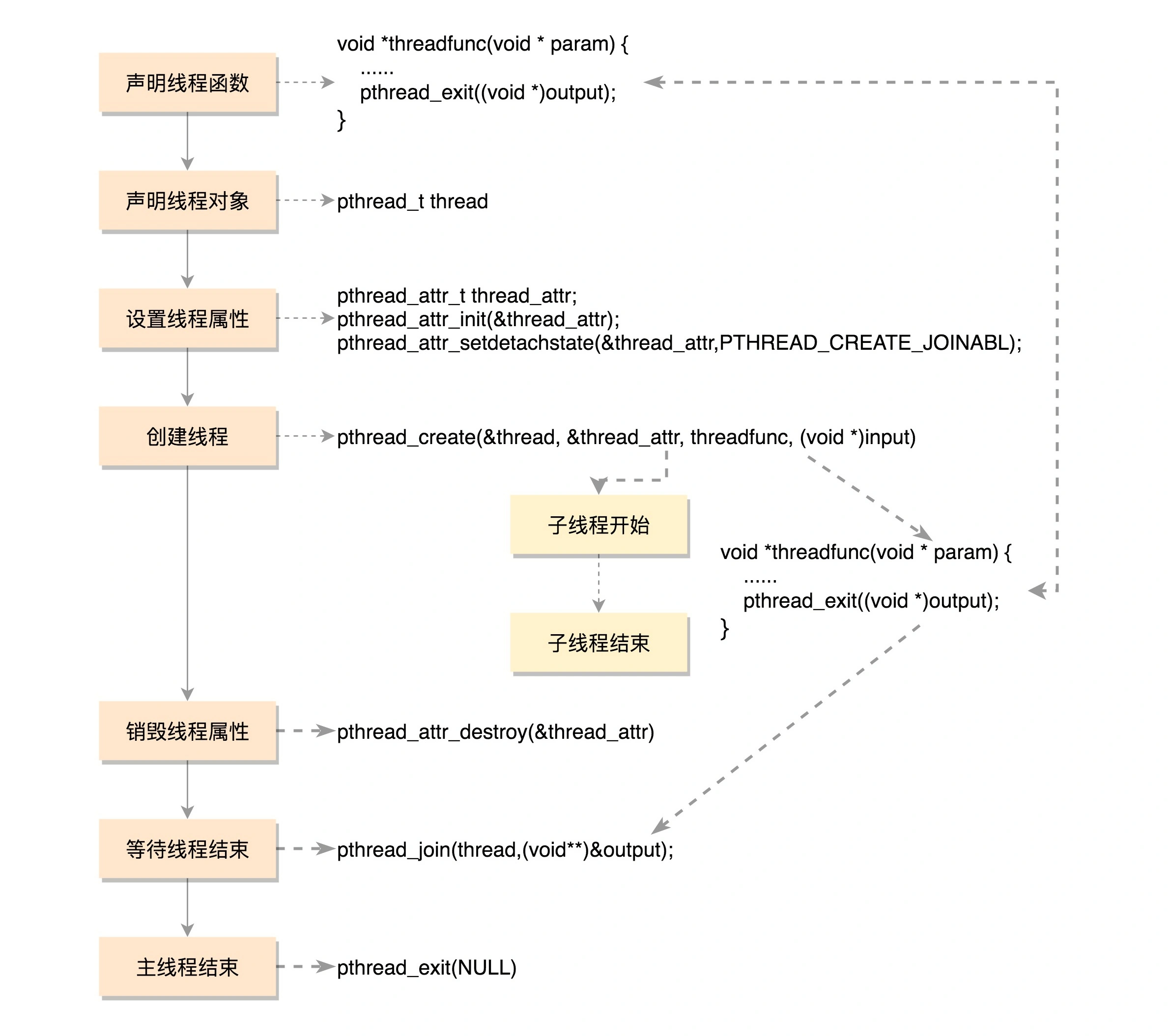
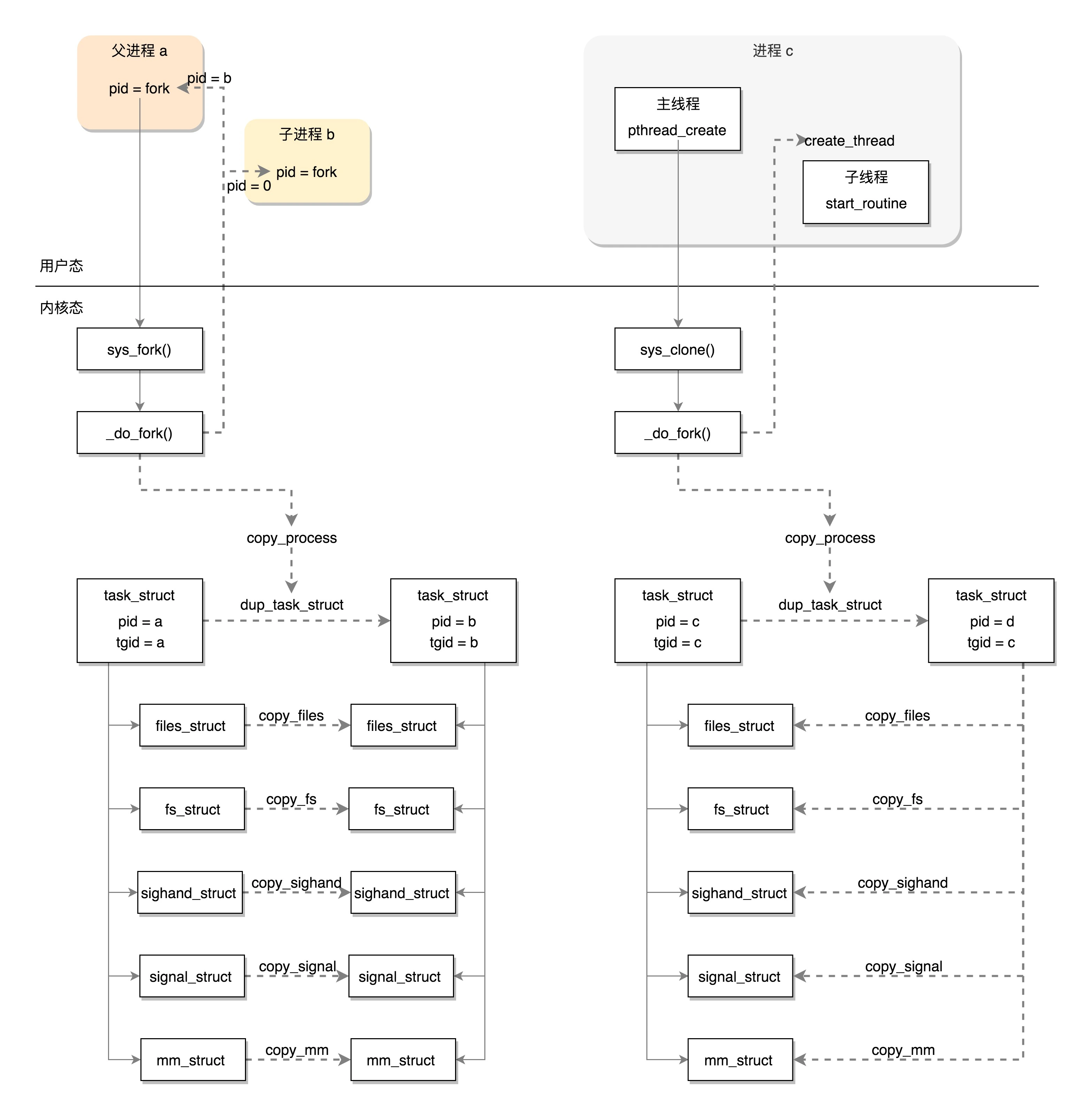
创建进程的话,调用的系统调用是 fork,在 copy_process 函数里面,会将五大结构 files_struct、fs_struct、sighand_struct、signal_struct、mm_struct 都复制一遍,从此父进程和子进程各用各的数据结构。而创建线程的话,调用的是系统调用 clone,在 copy_process 函数里面, 五大结构仅仅是引用计数加一,也即线程共享进程的数据结构
线程私有数据管理:
// 创建一个 key,伴随着一个析构函数
// key 一旦被创建,所有线程都可以访问它,但各线程可根据自己的需要往 key 中填入不同的值
int pthread_key_create(pthread_key_t *key, void (*destructor)(void*))
// 设置 key 对应的 value
int pthread_setspecific(pthread_key_t key, const void *value)
// 获取值
void *pthread_getspecific(pthread_key_t key)
内存管理
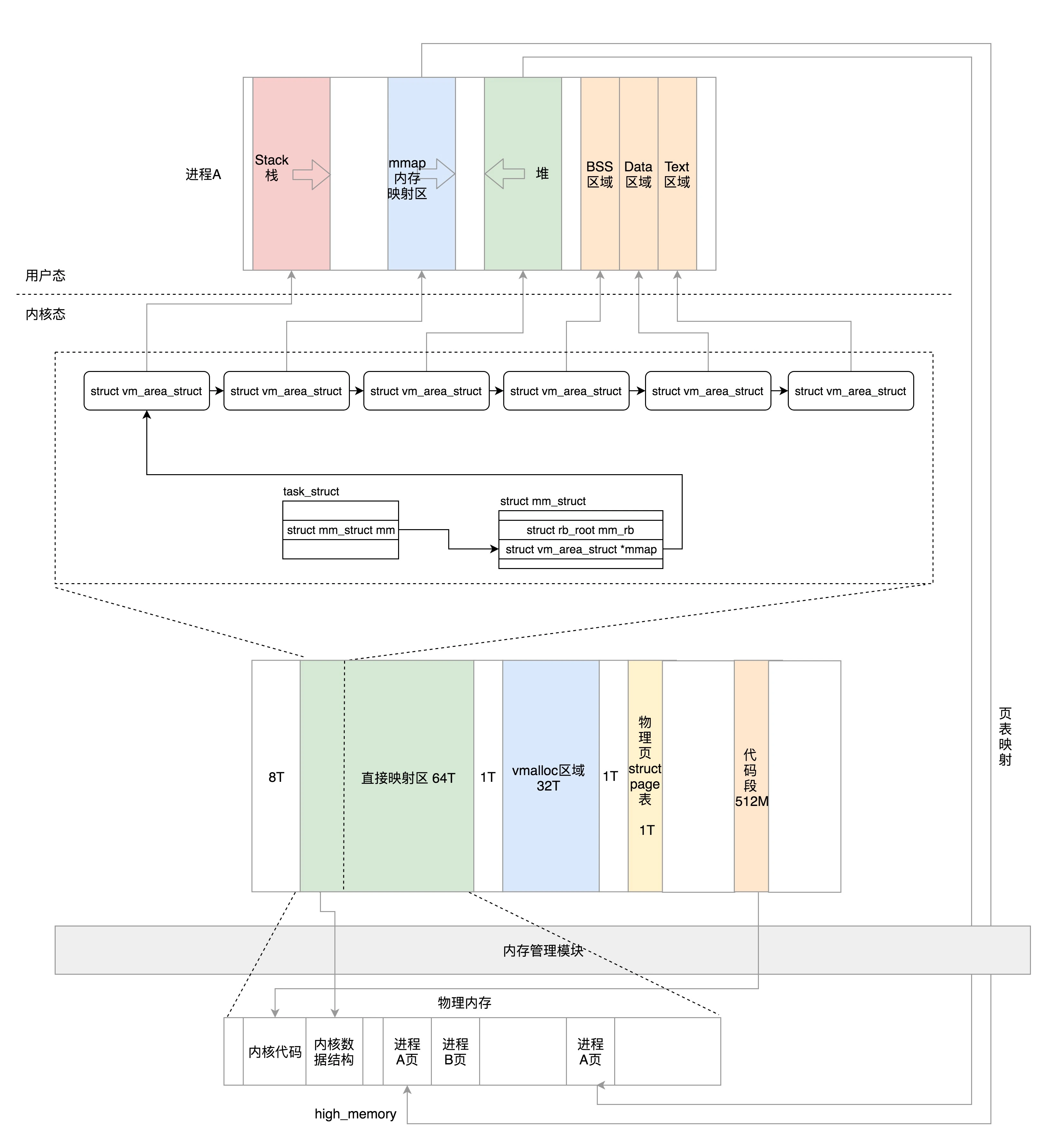
Linux 将虚拟地址空间分为内核空间跟用户空间
内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间
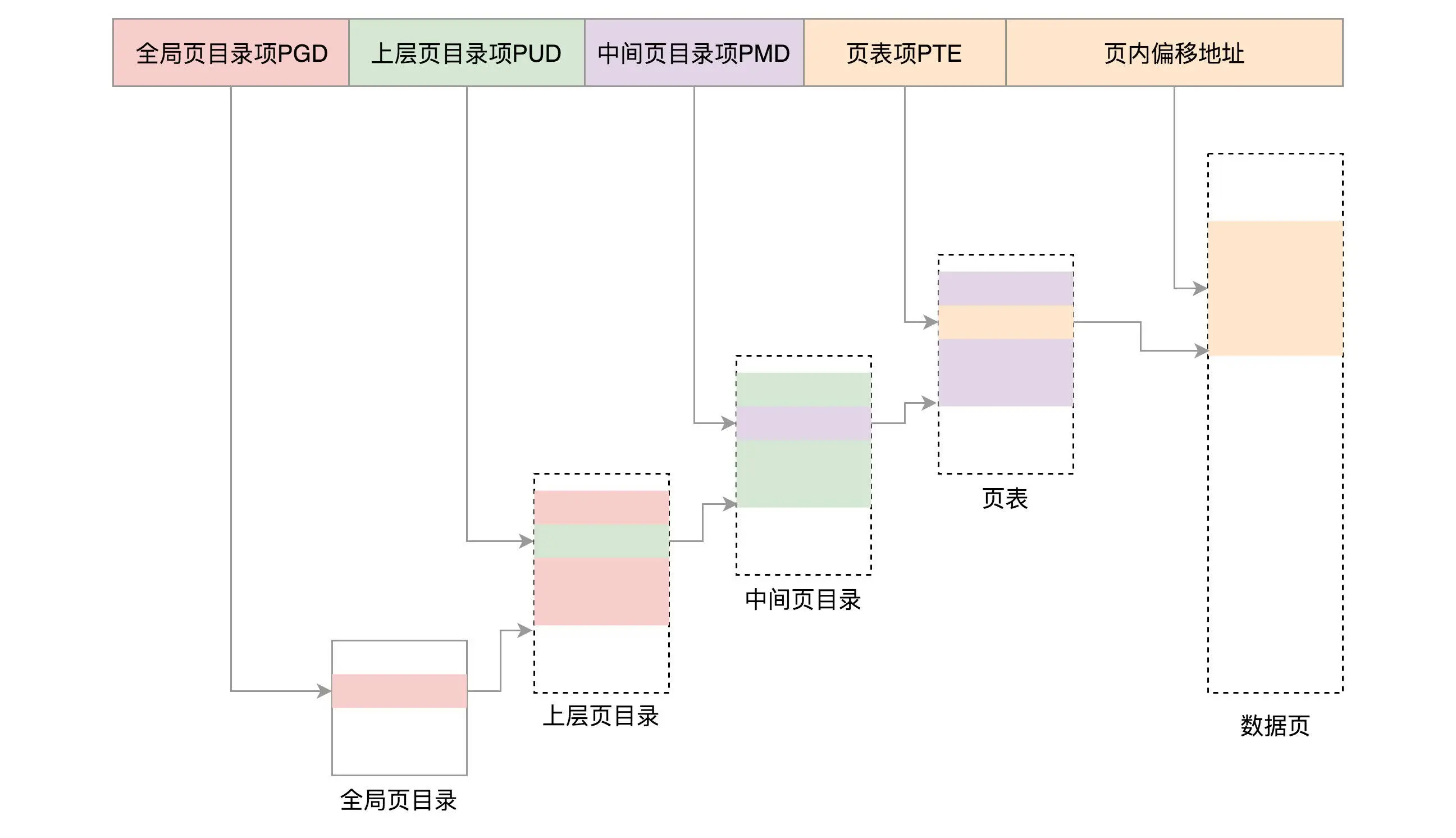
段表全称段描述符表(segment descriptors),放在全局描述符表 GDT(Global Descriptor Table)里面,所有的段的起始地址都是一样的
进程空间管理
在 struct mm_struct 里面,这些变量定义了代码、全局变量、堆、栈、内存映射区等区域的统计信息和位置
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
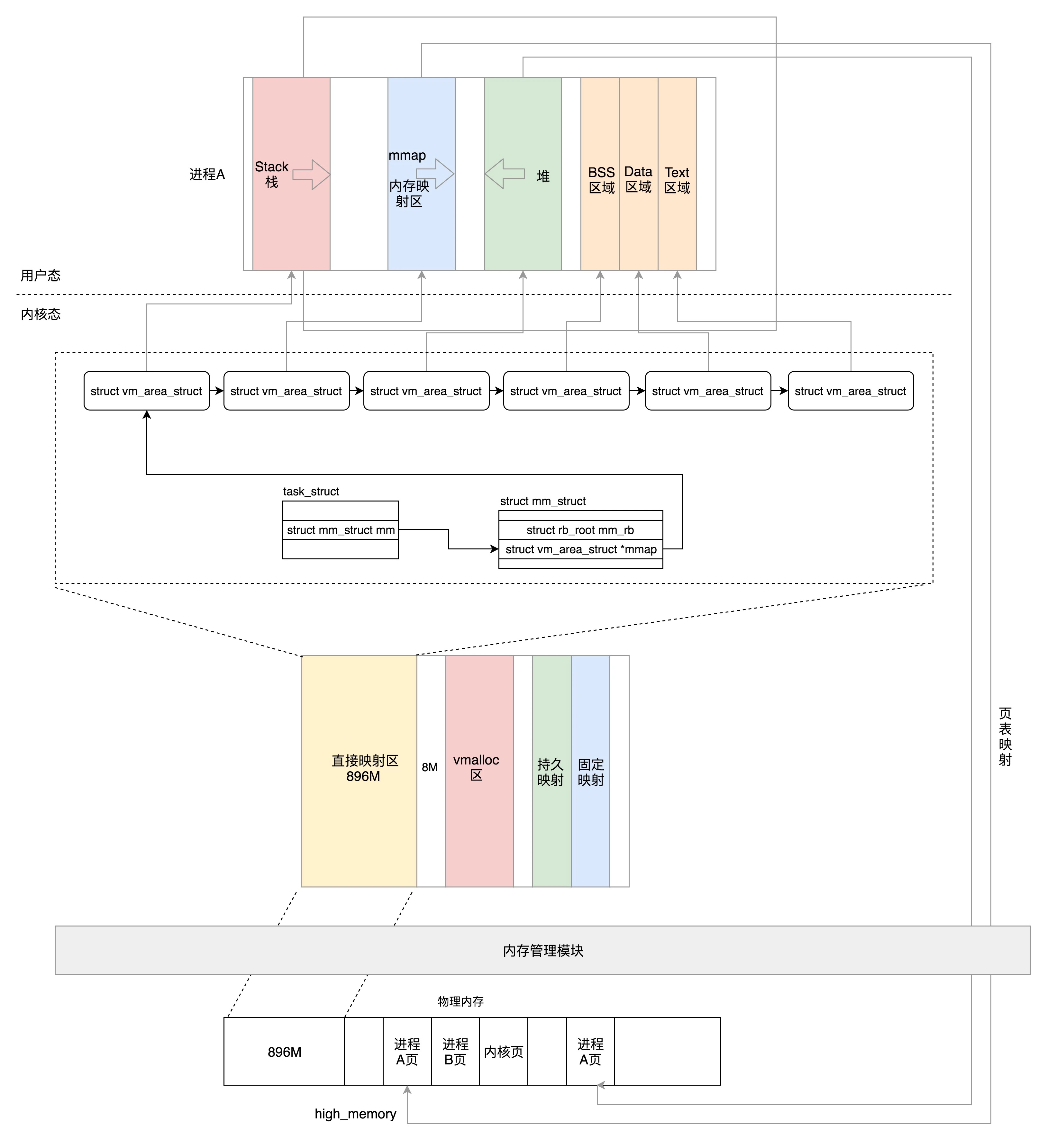
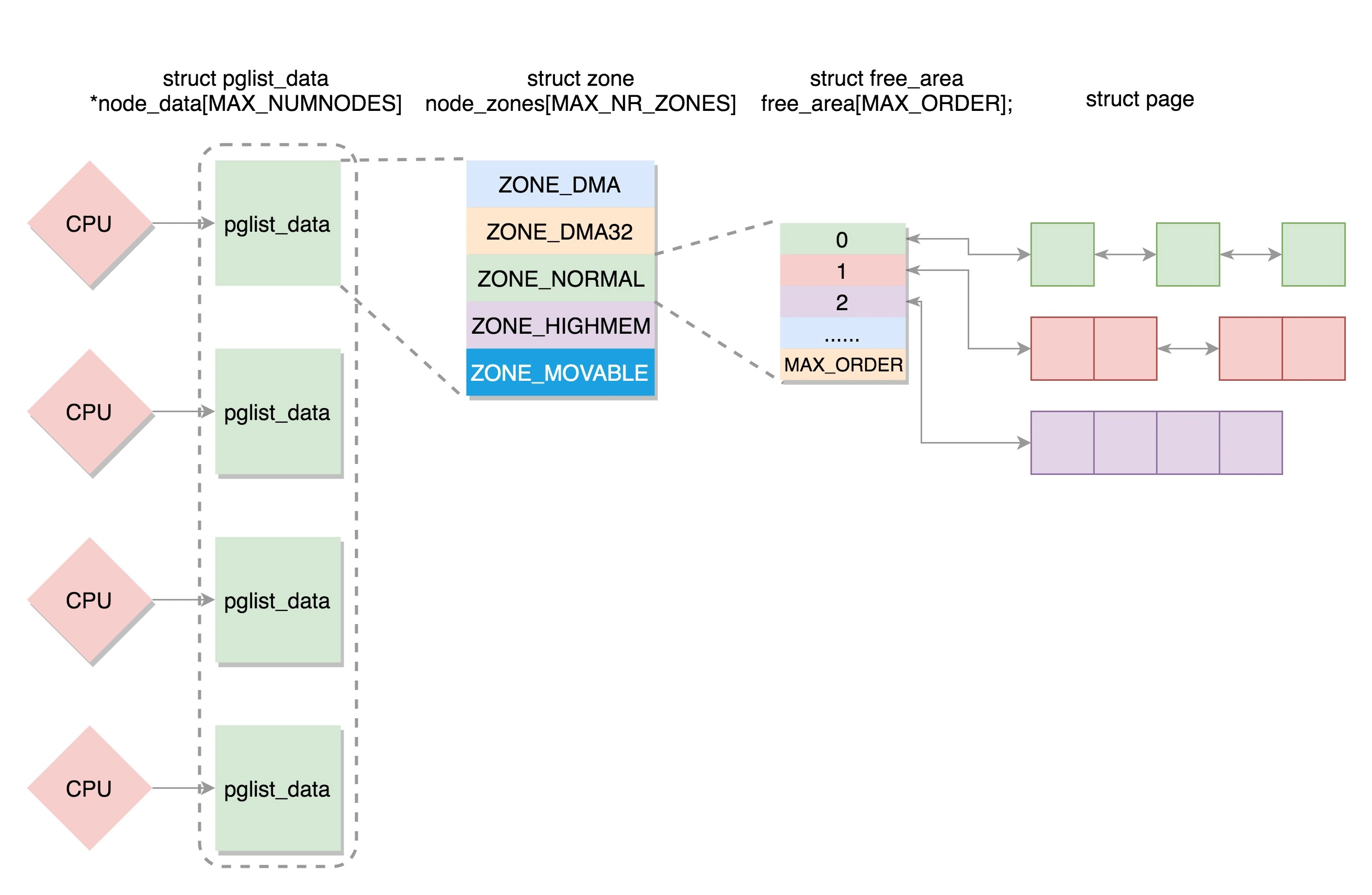
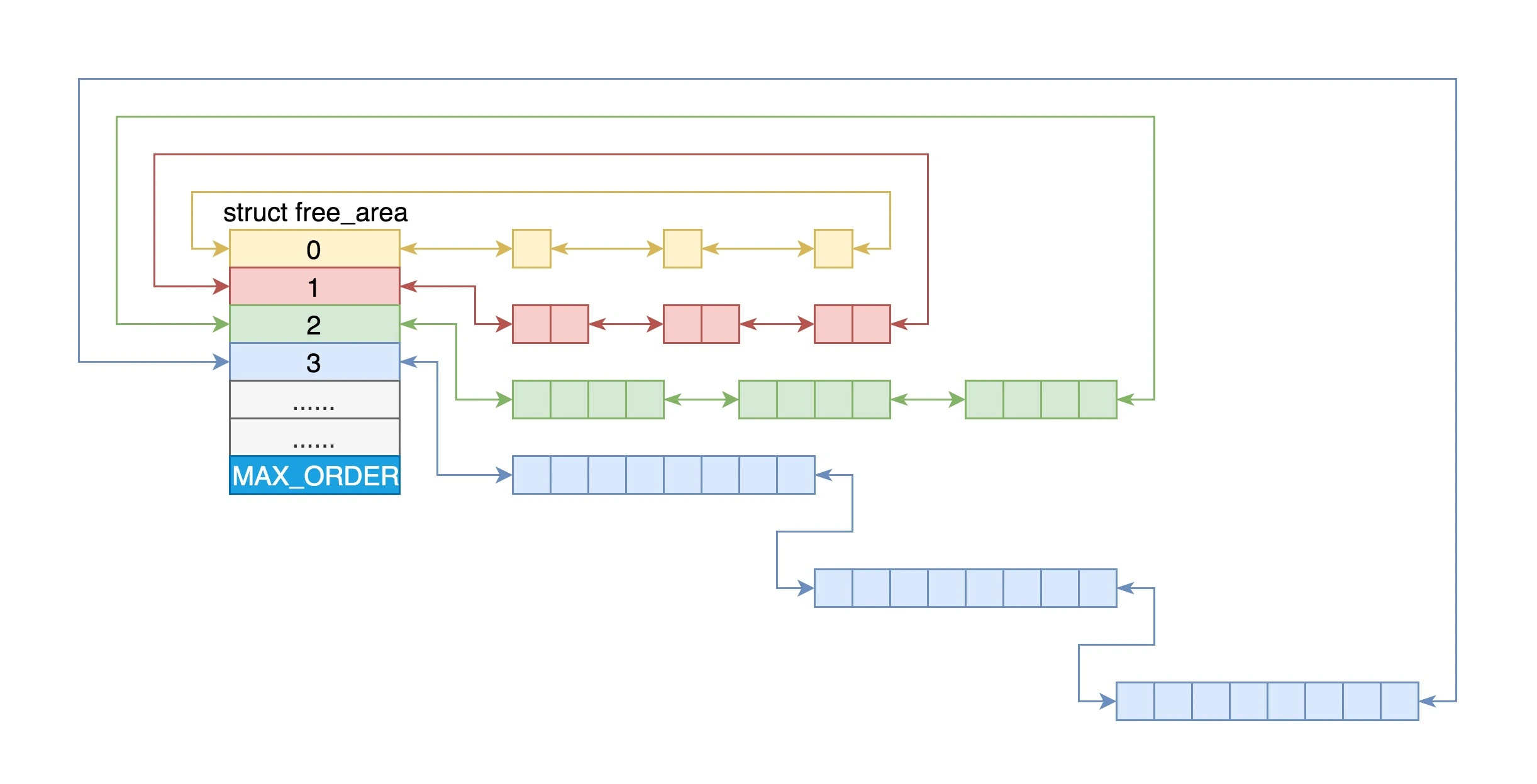
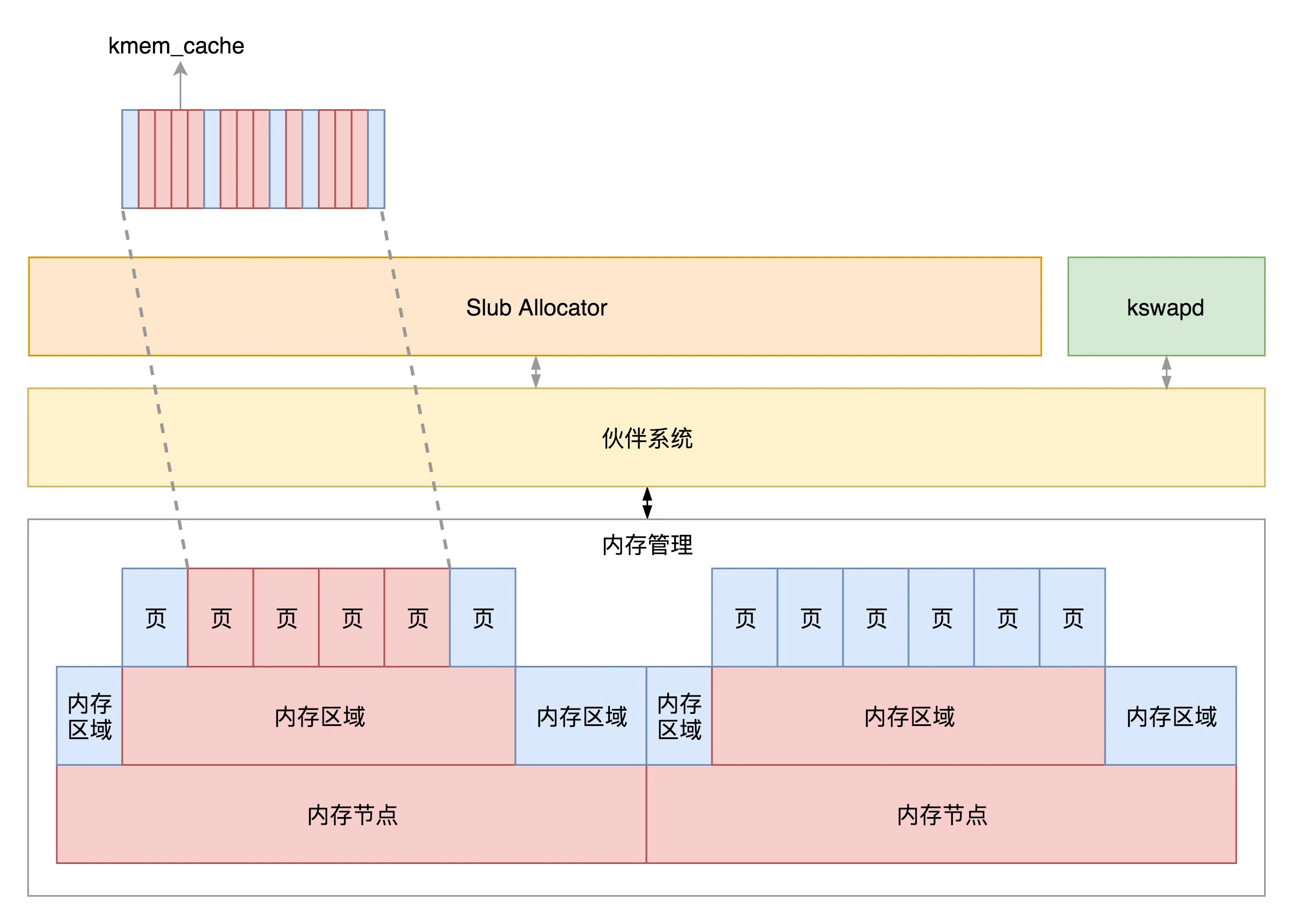
物理内存管理
- 如果有多个 CPU,那就有多个节点。每个节点用 struct pglist_data 表示
- 每个节点分为多个区域,每个区域用 struct zone 表示
- 每个区域分为多个页
- 伙伴系统将多个连续的页面作为一个大的内存块分配给上层
- kswapd 负责物理页面的换入换出
- Slub Allocator 将从伙伴系统申请的大内存块切成小块,分配给其他系统
用户态内存映射
内存映射不仅仅是物理内存和虚拟内存之间的映射,还包括将文件中的内容映射到虚拟内存空间
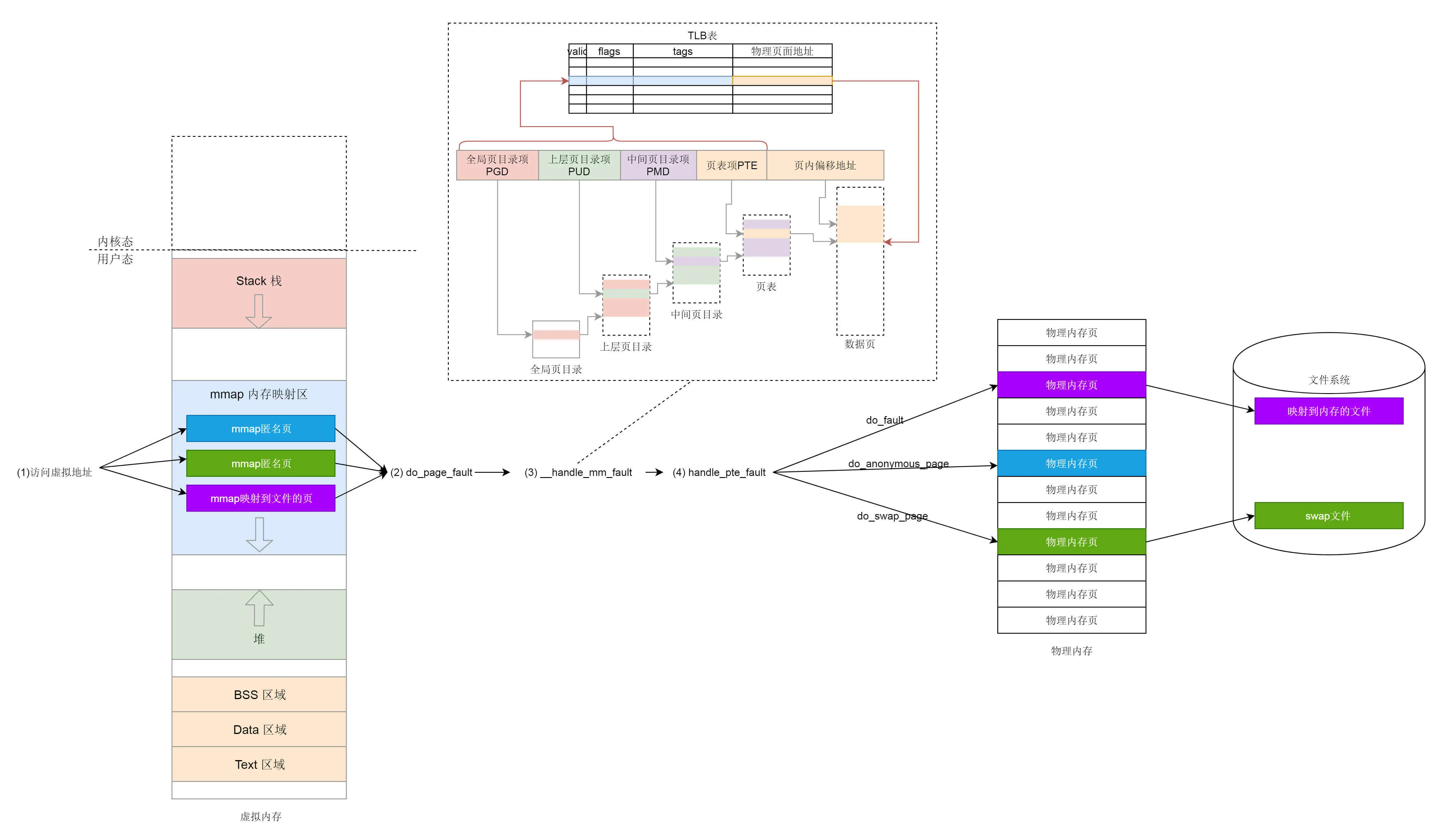
内核态内存映射
- kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- kmalloc保证分配的内存在物理上是连续的,内存只有在要被DMA访问的时候才需要物理上连续,malloc和vmalloc保证的是在虚拟地址空间上的连续
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- vmalloc比kmalloc要慢。
尽管在某些情况下才需要物理上连续的内存块,但是很多内核代码都用kmalloc来获得内存,而不是vmalloc。这主要是出于性能的考虑。vmalloc函数为了把物理内存上不连续的页转换为虚拟地址空间上连续的页,必须专门建立页表项。糟糕的是,通过vmalloc获得的页必须一个个地进行映射,因为它们物理上是不连续的,这就会导致比直接内存映射大得多的TLB抖动,vmalloc仅在不得已时才会用--典型的就是为了获得大块内存时。
文件系统
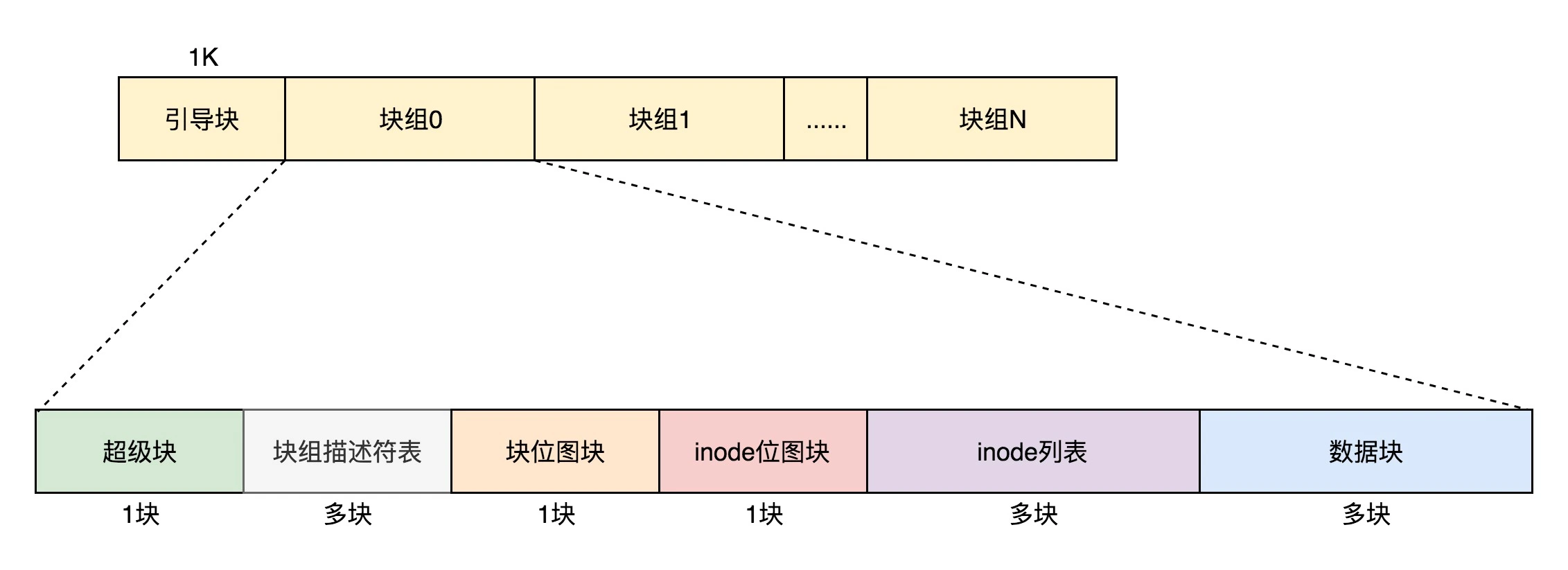
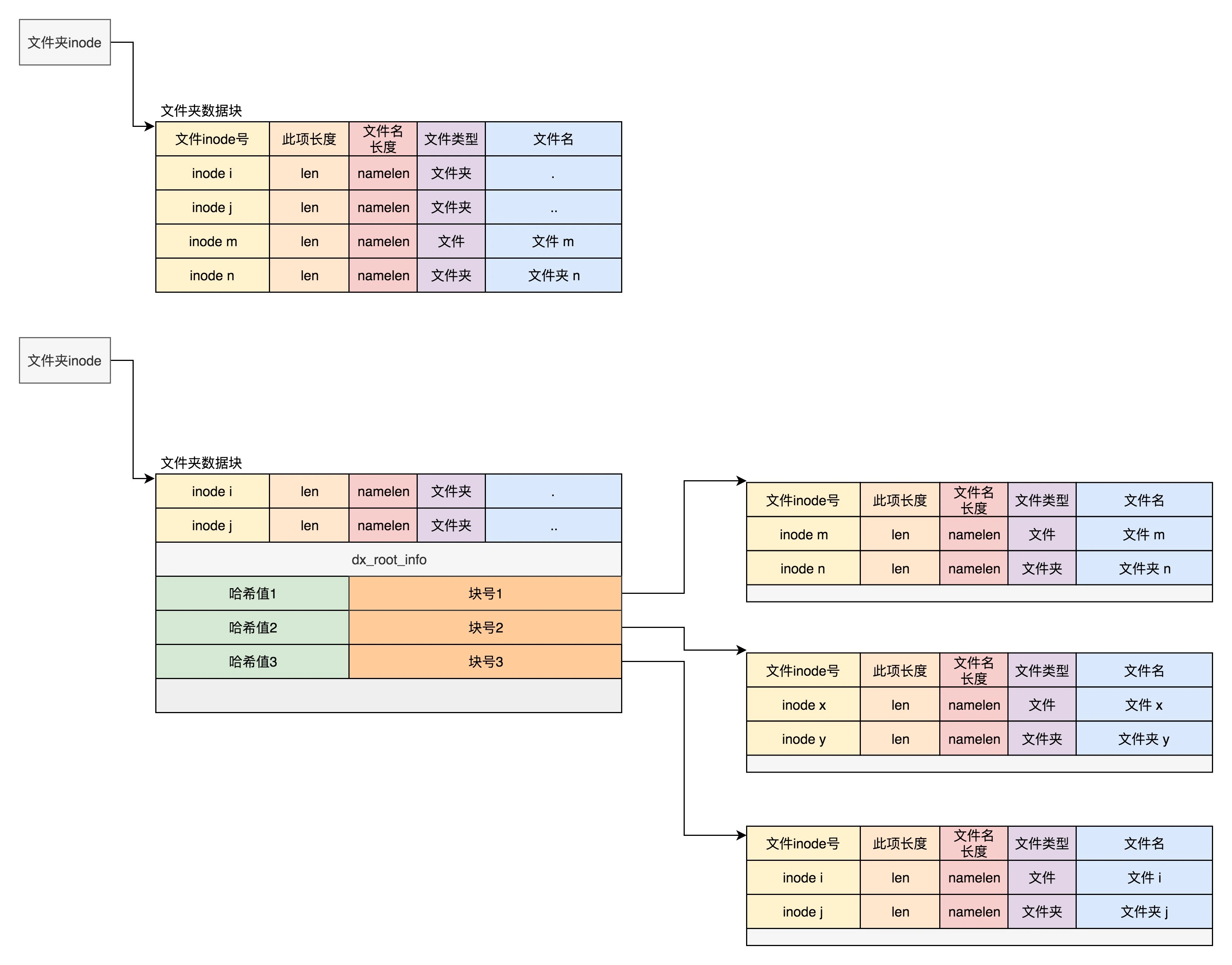
硬盘文件系统
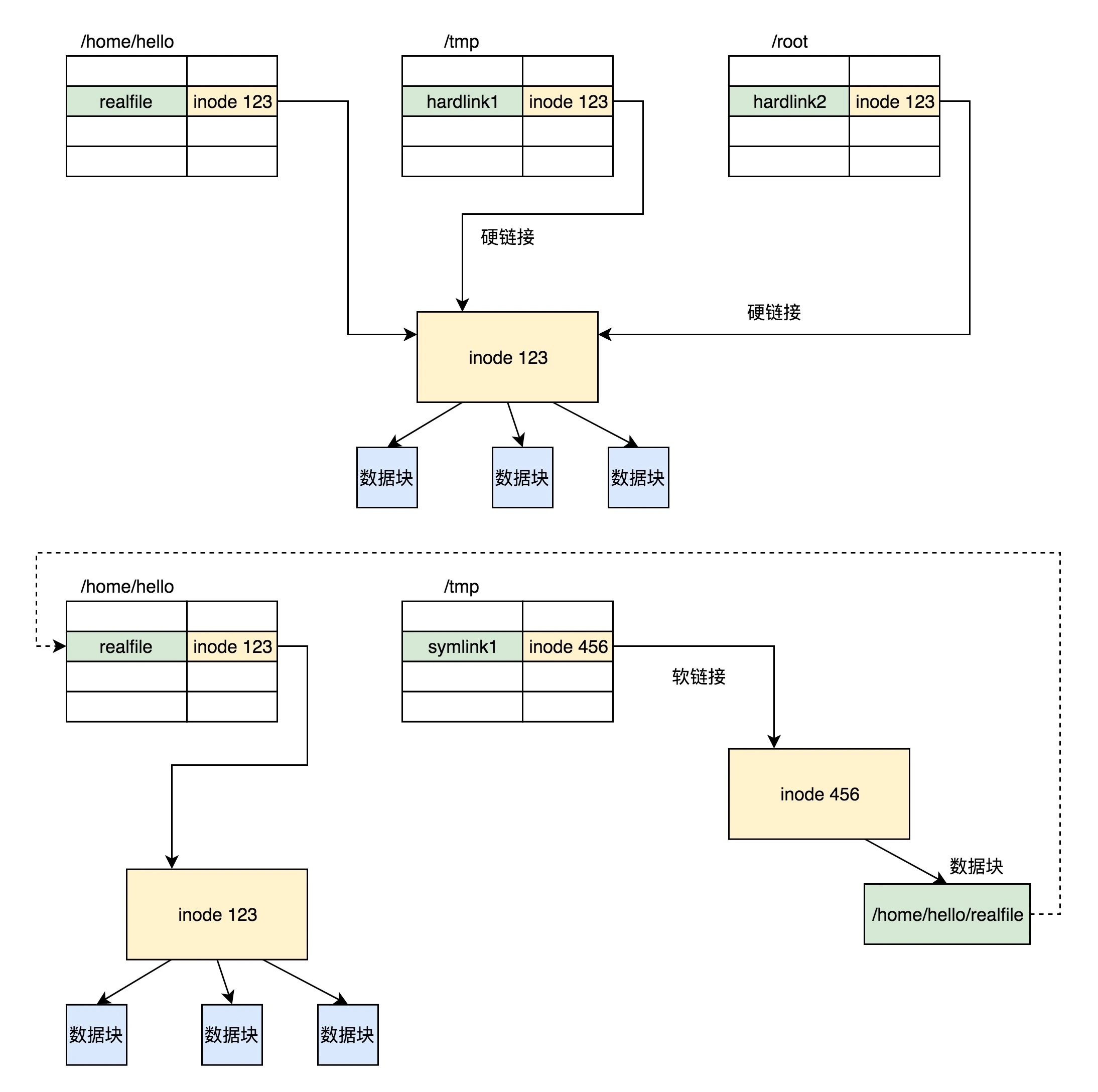
每个文件都会对应一个 inode;一个文件夹就是一个文件,也对应一个 inode
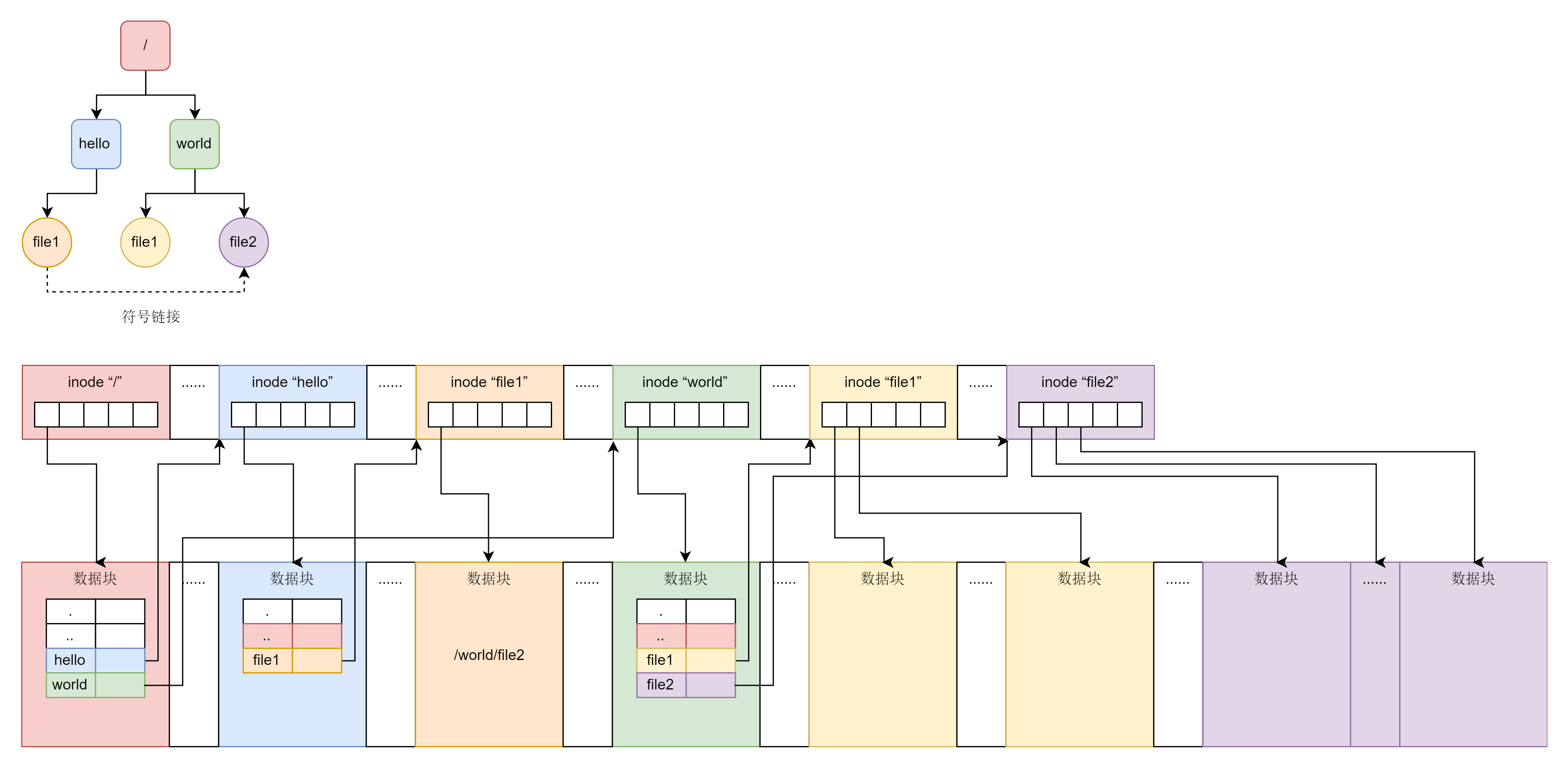
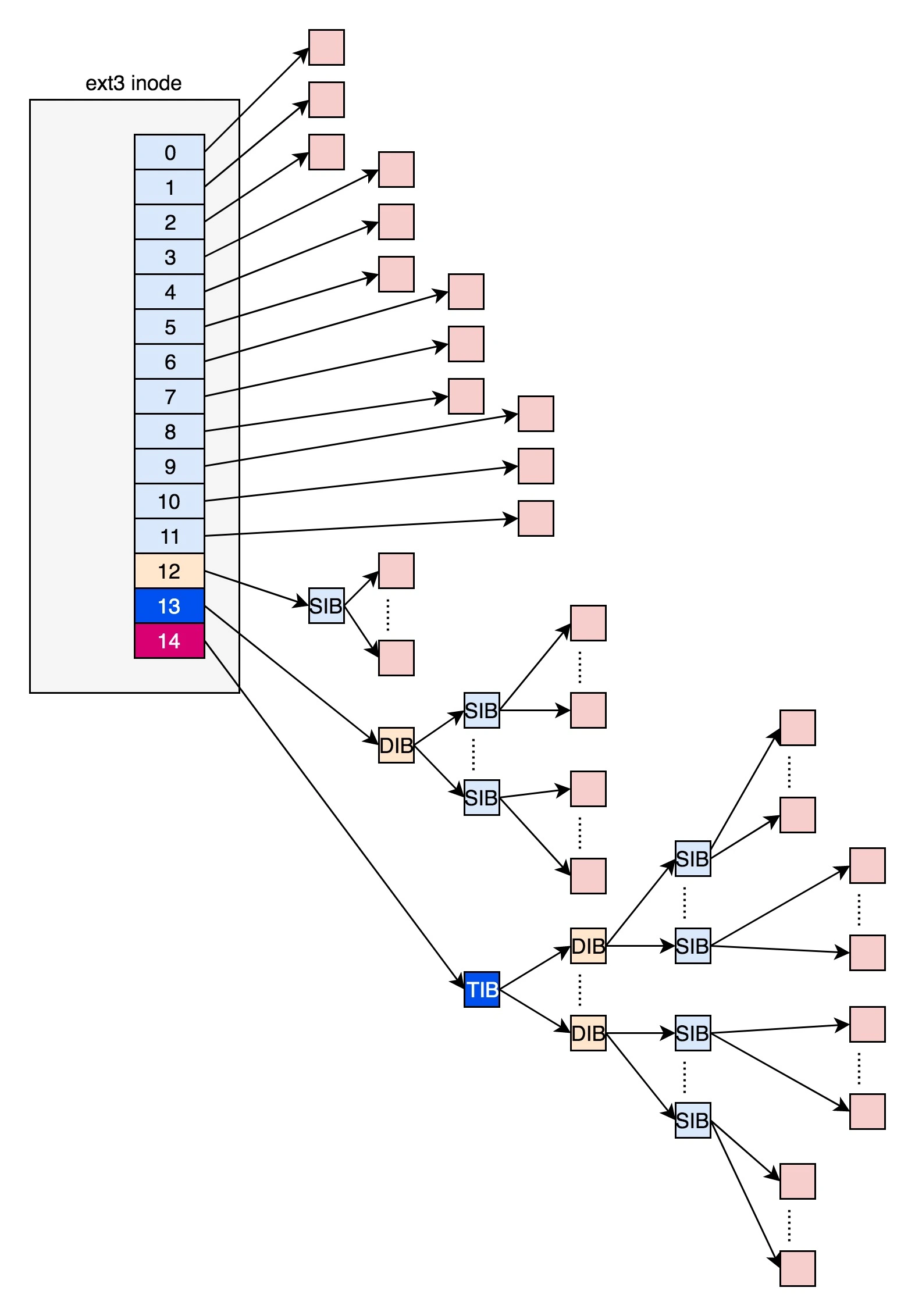
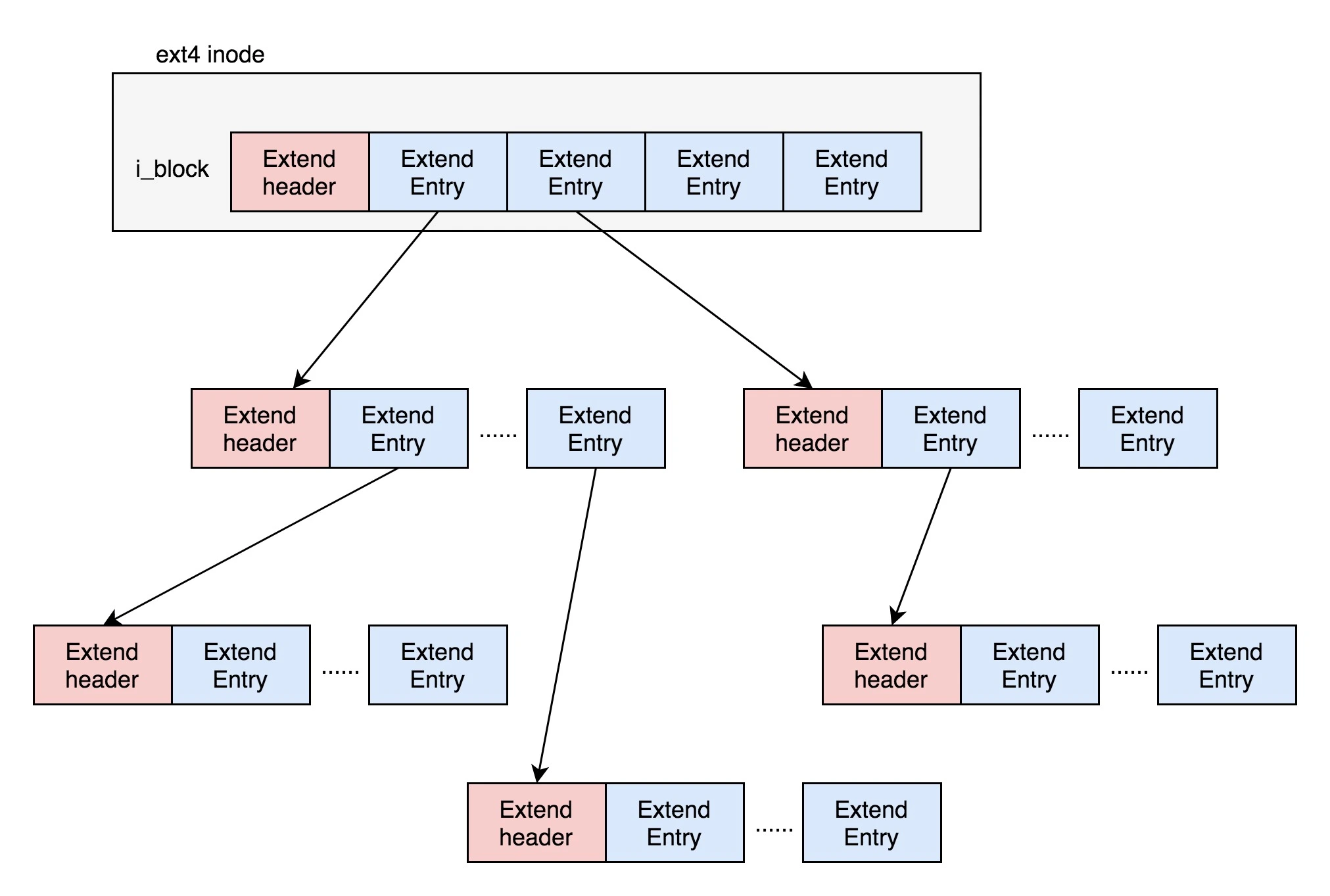
位图:用来记录哪些块是空闲,哪些块已经被使用
虚拟文件系统
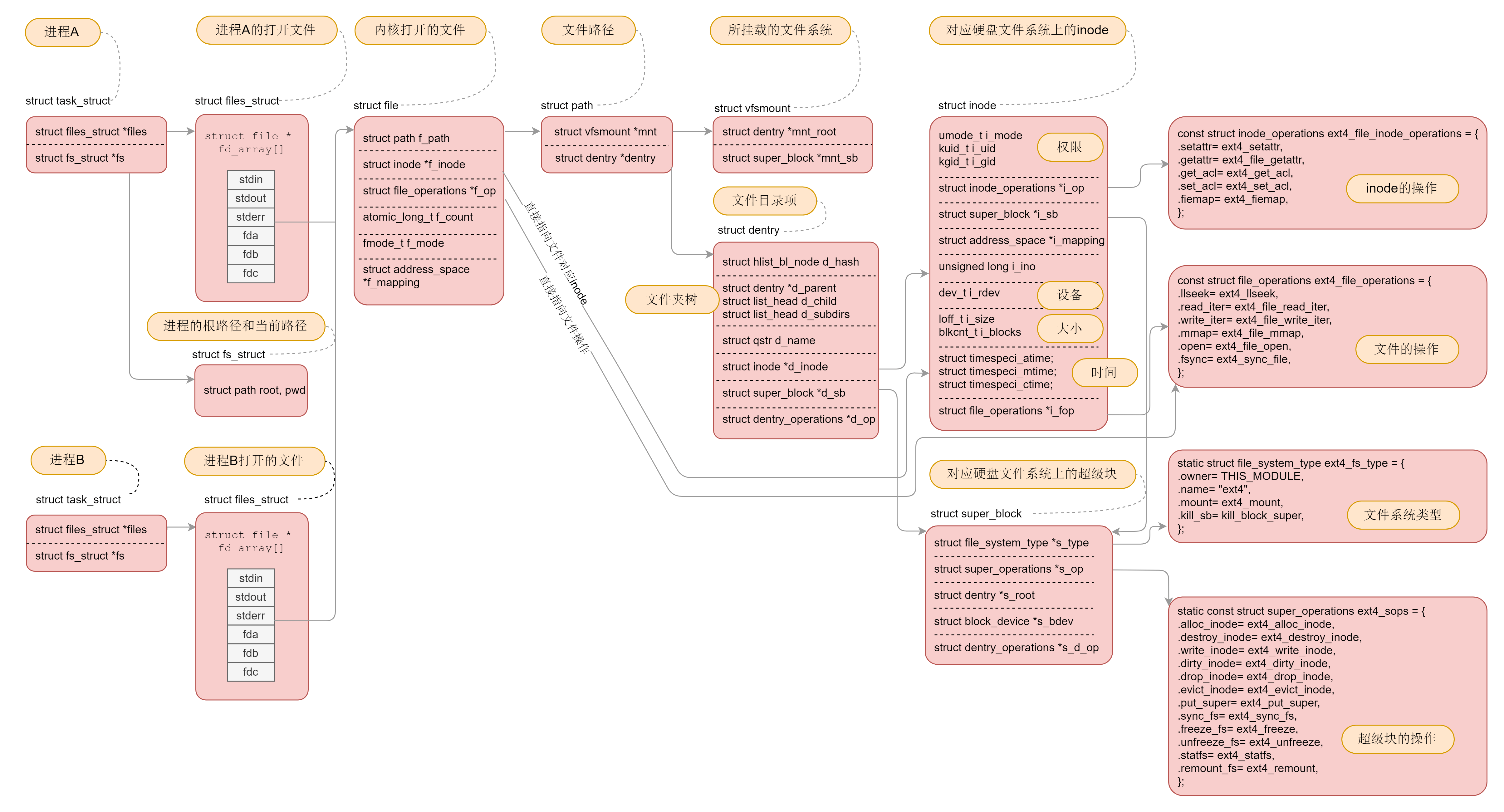
挂载
想要操作文件系统,第一件事情就是注册文件系统:
register_filesystem(&ext4_fs_type);
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
如果一种文件系统的类型曾经在内核注册过,这就说明允许你挂载并且使用这个文件系统
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
......
root = type->mount(type, flags, name, data);
......
sb = root->d_sb;
......
}
打开文件
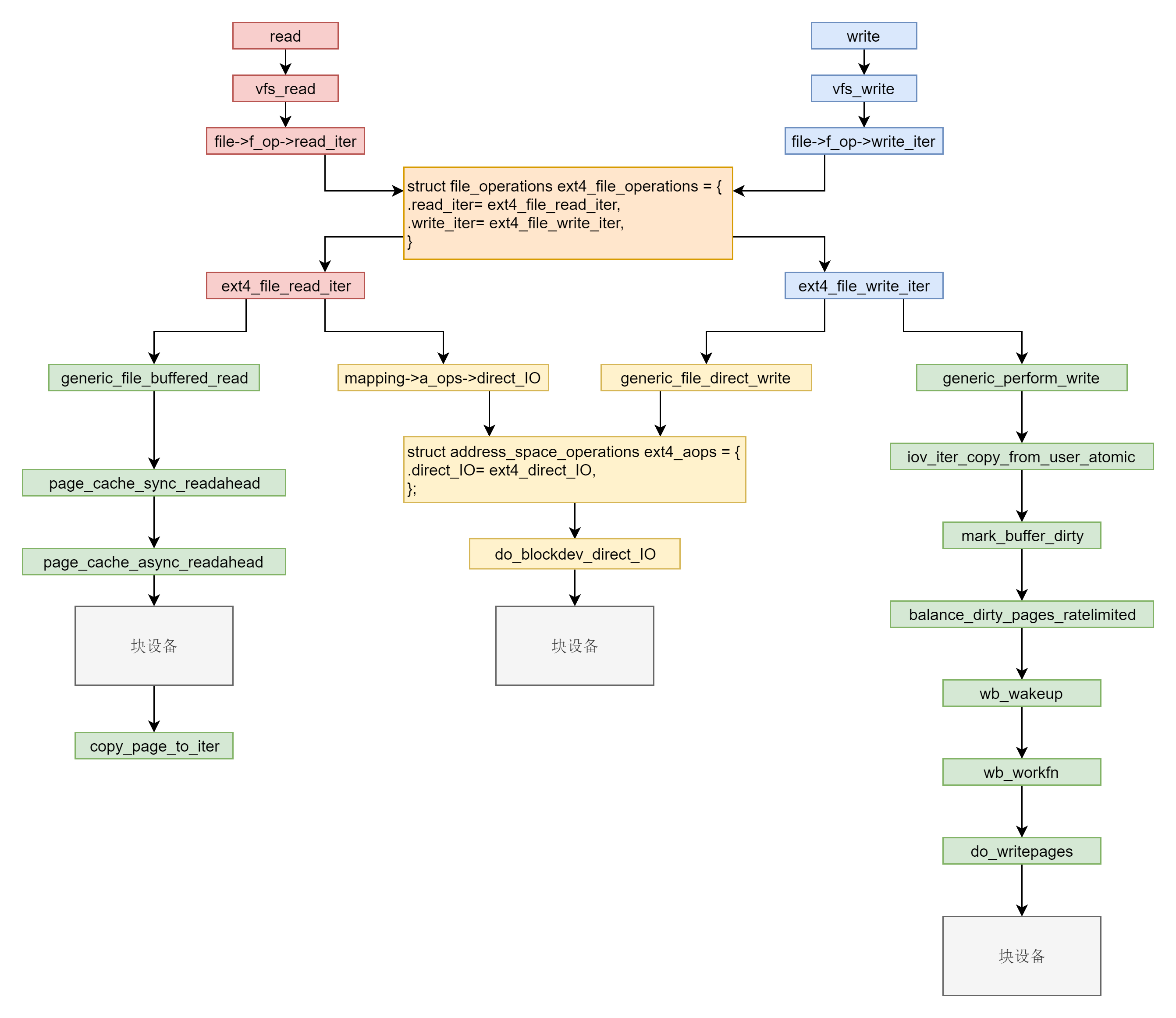
文件缓存
- 缓存 I/O:大多数文件系统的默认 I/O 操作都是缓存 I/O
- 读操作:先查缓存,没有再读磁盘
- 写操作:批量写到内存,再统一刷到磁盘,或者显式调用sync
- 直接 IO:就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制
输入输出系统
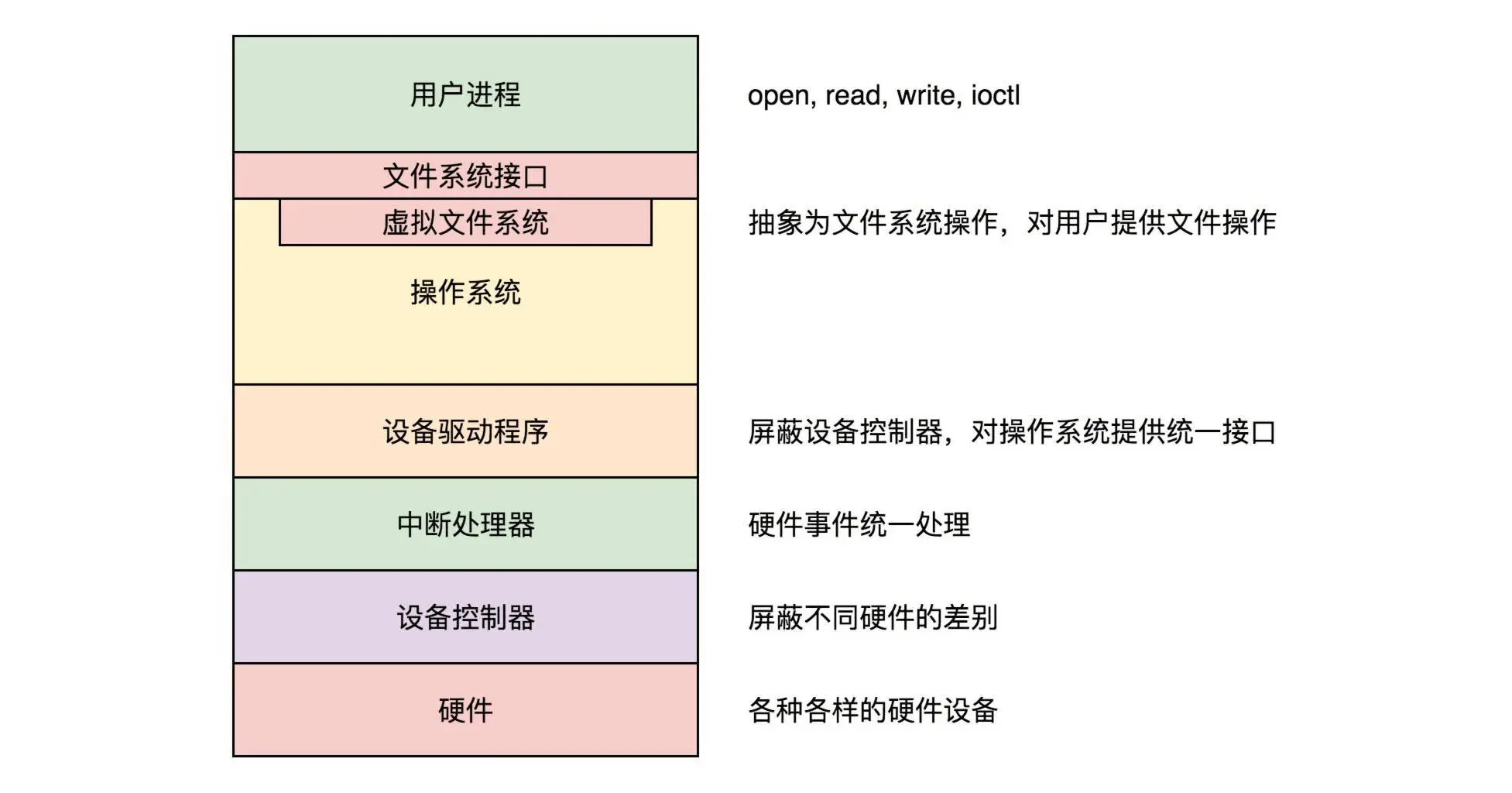
除了常规的软硬件IO控制,Linux通过文件系统接口屏蔽驱动程序的差异
操作设备,都是基于文件系统的接口
- /sys/devices 是内核对系统中所有设备的分层次的表示
- /sys/dev 目录下一个 char 文件夹,一个 block 文件夹,分别维护一个按字符设备和块设备的主次号码 (major:minor) 链接到真实的设备 (/sys/devices 下) 的符号链接文件
- /sys/block 是系统中当前所有的块设备
- /sys/module 有系统中所有模块的信息
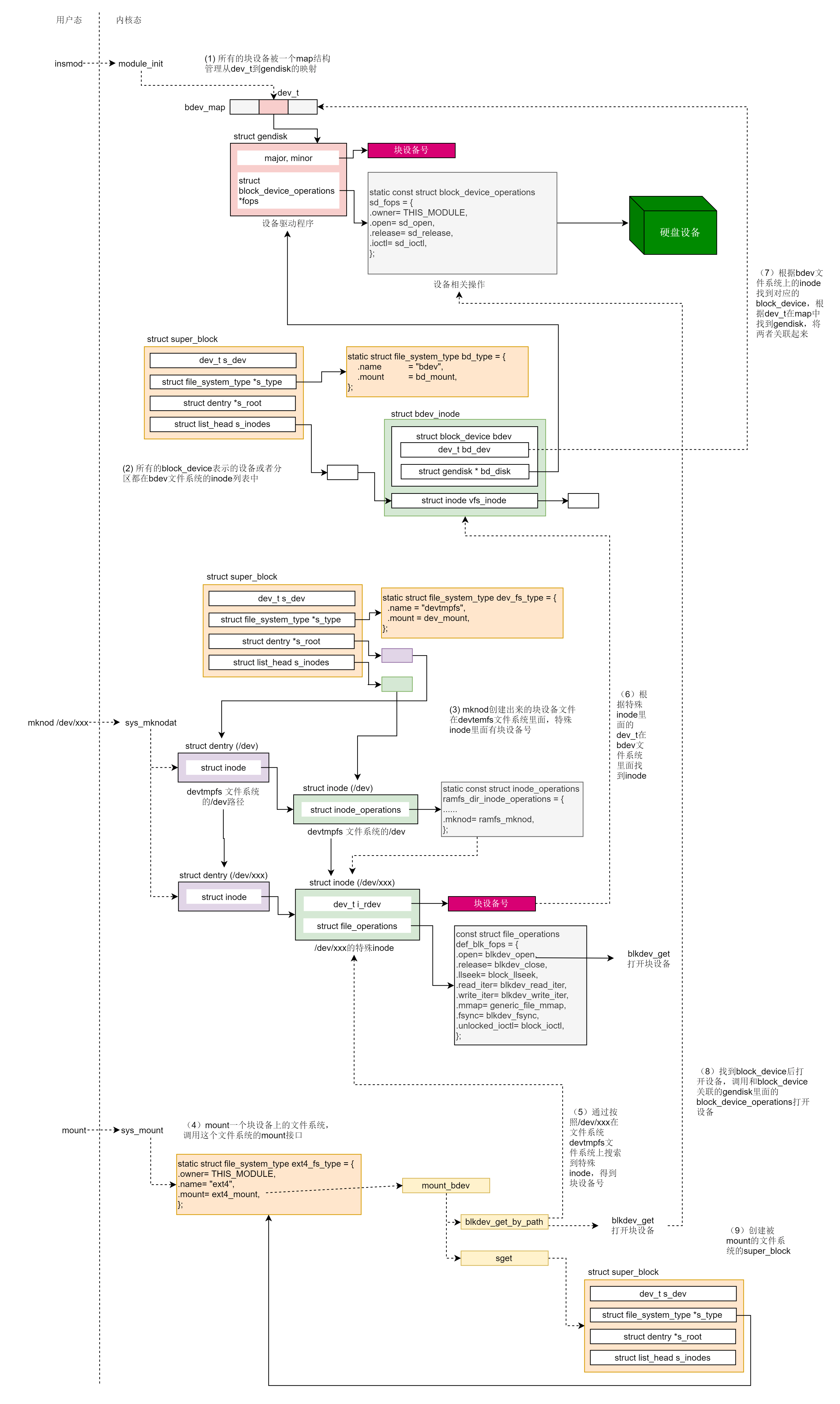
字符设备
工作的条件:
- 要有设备驱动程序的 ko 模块,里面有模块初始化函数、中断处理函数、设备操作函数。这里面封装了对于外部设备的操作,初始化函数在加载驱动被调用,会在内核维护所有字符设备驱动的数据结构 cdev_map 里面注册自己的设备号
- /dev 目录下有一个文件表示这个设备,里面有inode存储设备号,可以通过设备号在 cdev_map 中找到设备驱动程序
- 打开一个字符设备文件和打开一个普通的文件有类似的数据结构,有文件描述符、有 struct file、指向字符设备文件的 dentry 和 inode,写一个字符设备文件会变成读写外部设备
块设备
进程间通信
- 消息模型
- 共享内存模型
- 信号量
管道模型
- 命令之间的 |
- 手动创建管道 mkfifo hello
管道是内核里面的一串缓存
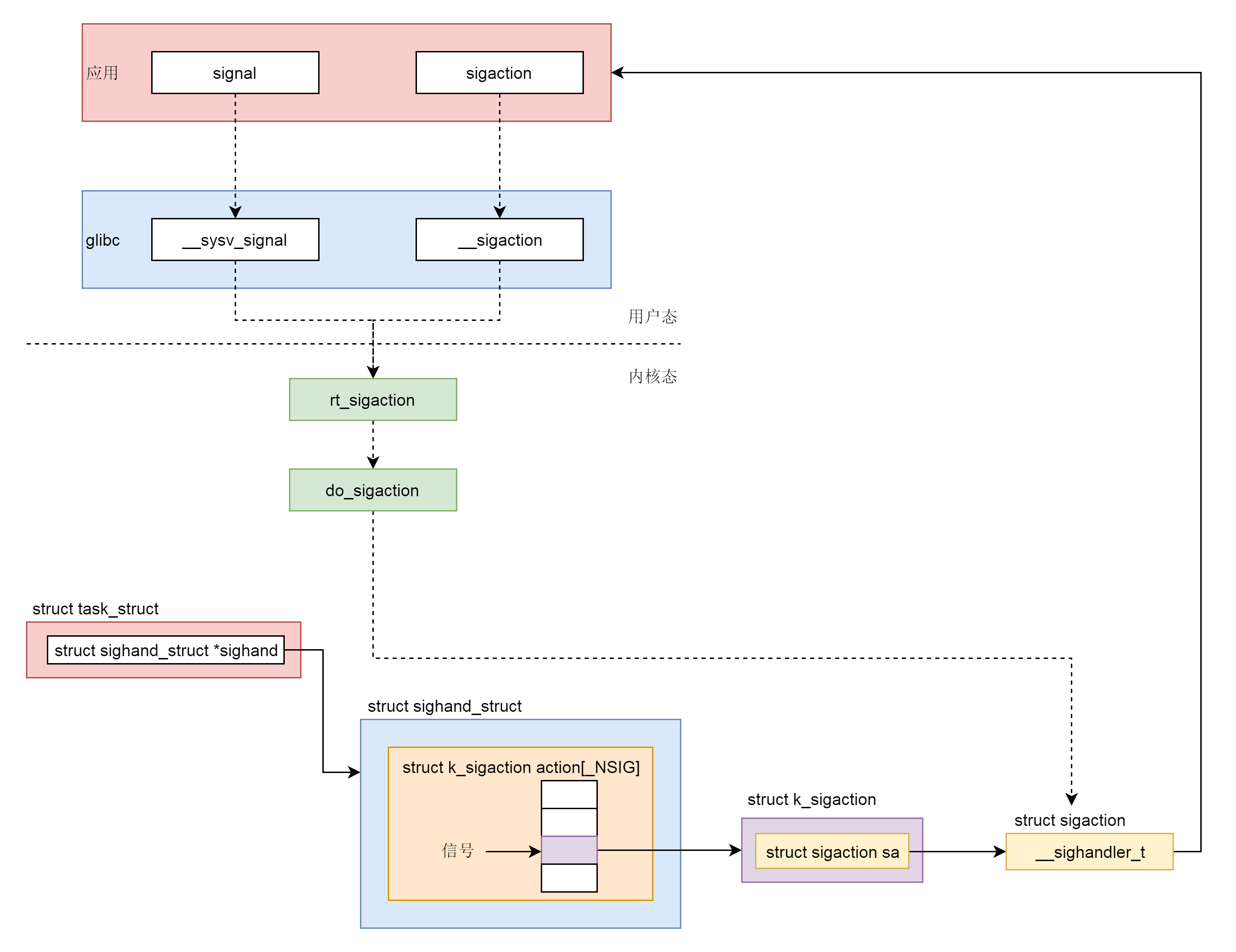
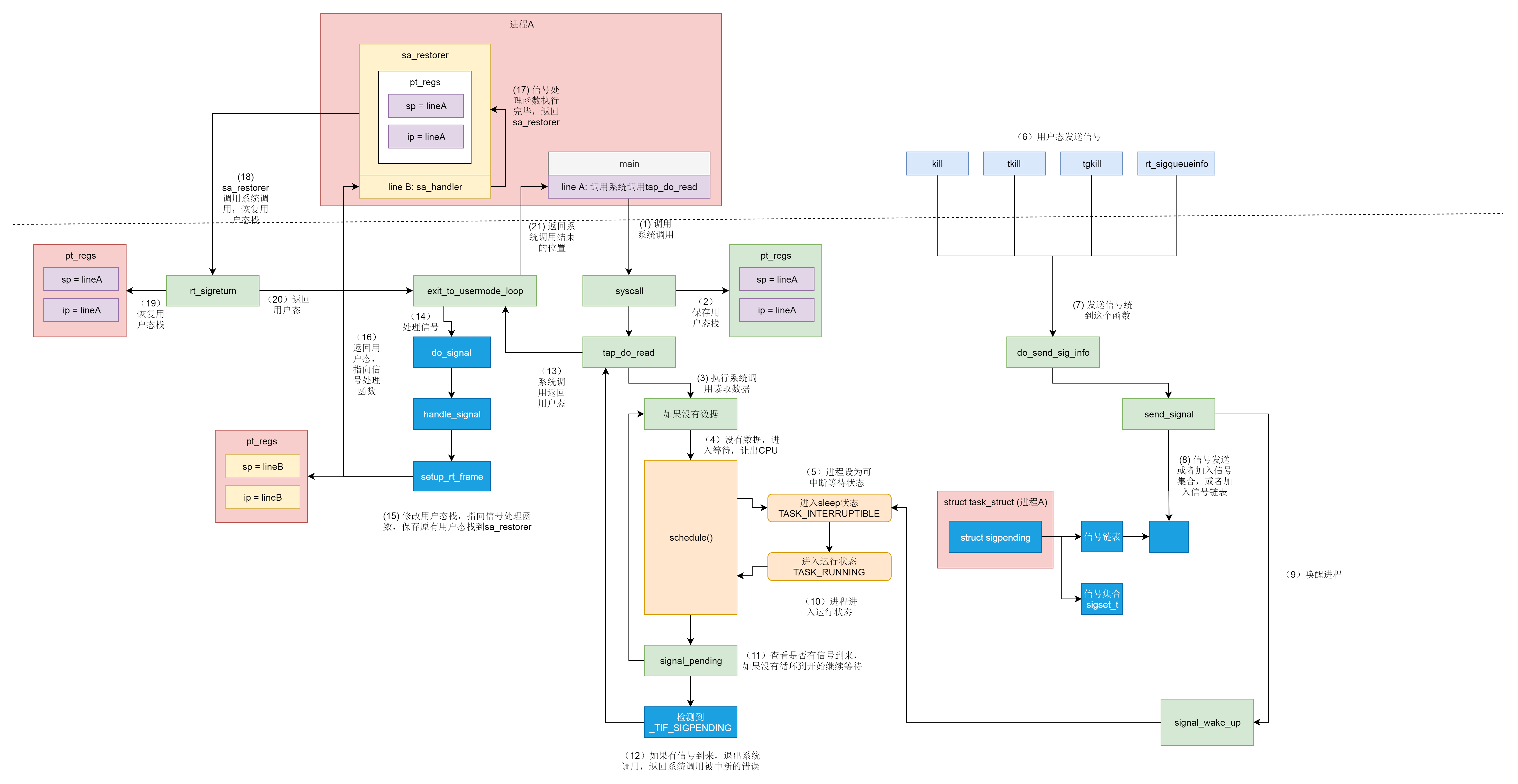
信号
中断要注册中断处理函数,但是中断处理函数是在内核驱动里面的,信号也要注册信号处理函数,信号处理函数是在用户态进程里面的。
用户进程对信号的处理方式:
- 执行默认操作
- 捕获并覆写默认操作
- 忽略
// 设置信号处理的方式
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);
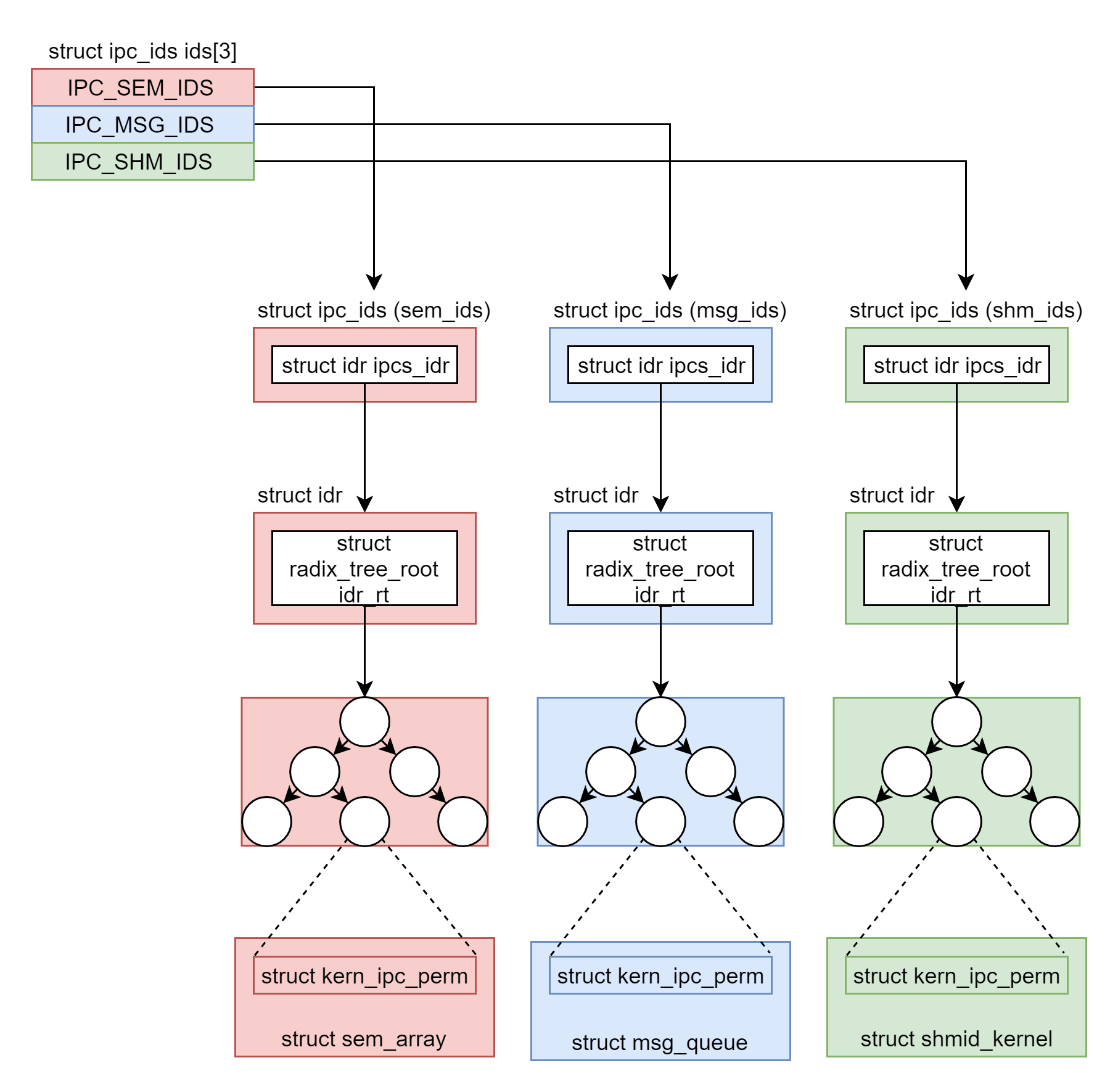
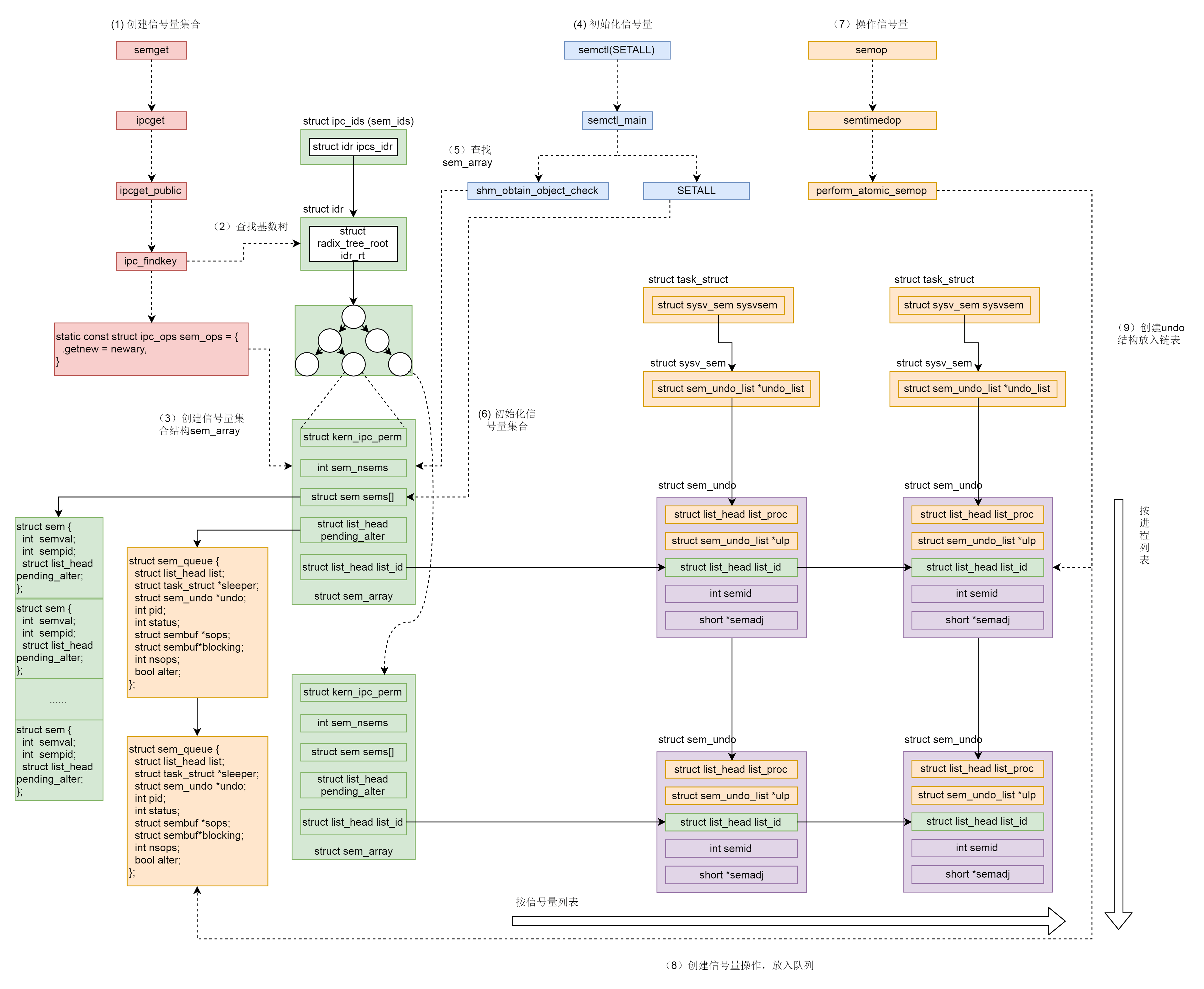
IPC机制
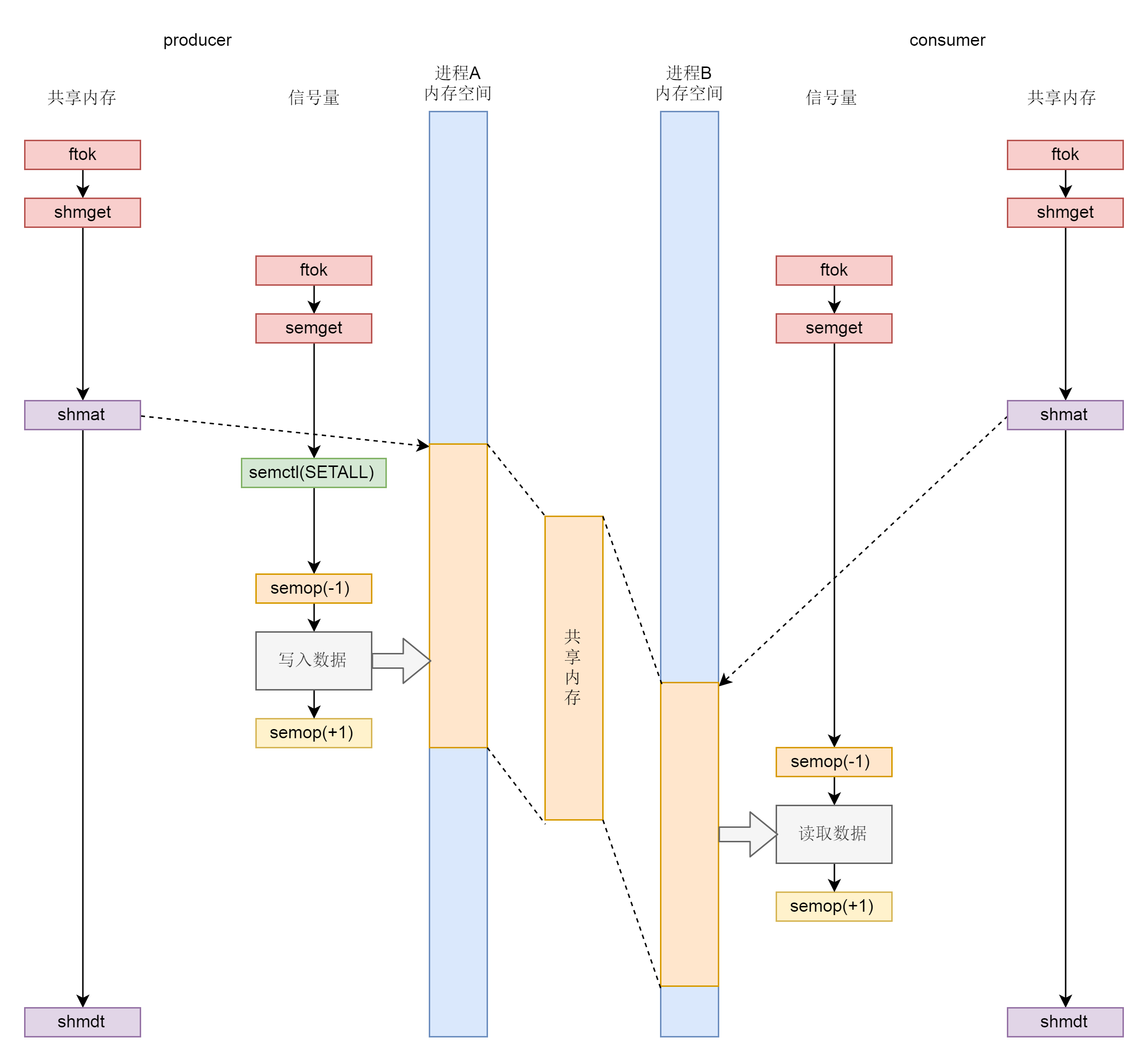
使用之前都要生成 key,然后通过 key 得到唯一的 id,并且都是通过 xxxget 函数,这三种进程间通信机制是使用统一的机制管理起来的,都叫 ipcxxx
struct ipc_namespace {
......
struct ipc_ids ids[3];
......
}
#define IPC_SEM_IDS 0
#define IPC_MSG_IDS 1
#define IPC_SHM_IDS 2
#define sem_ids(ns) ((ns)->ids[IPC_SEM_IDS])
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])
#define shm_ids(ns) ((ns)->ids[IPC_SHM_IDS])
struct ipc_ids {
int in_use;
unsigned short seq;
struct rw_semaphore rwsem;
struct idr ipcs_idr;
int next_id;
};
struct idr {
struct radix_tree_root idr_rt;
unsigned int idr_next;
};
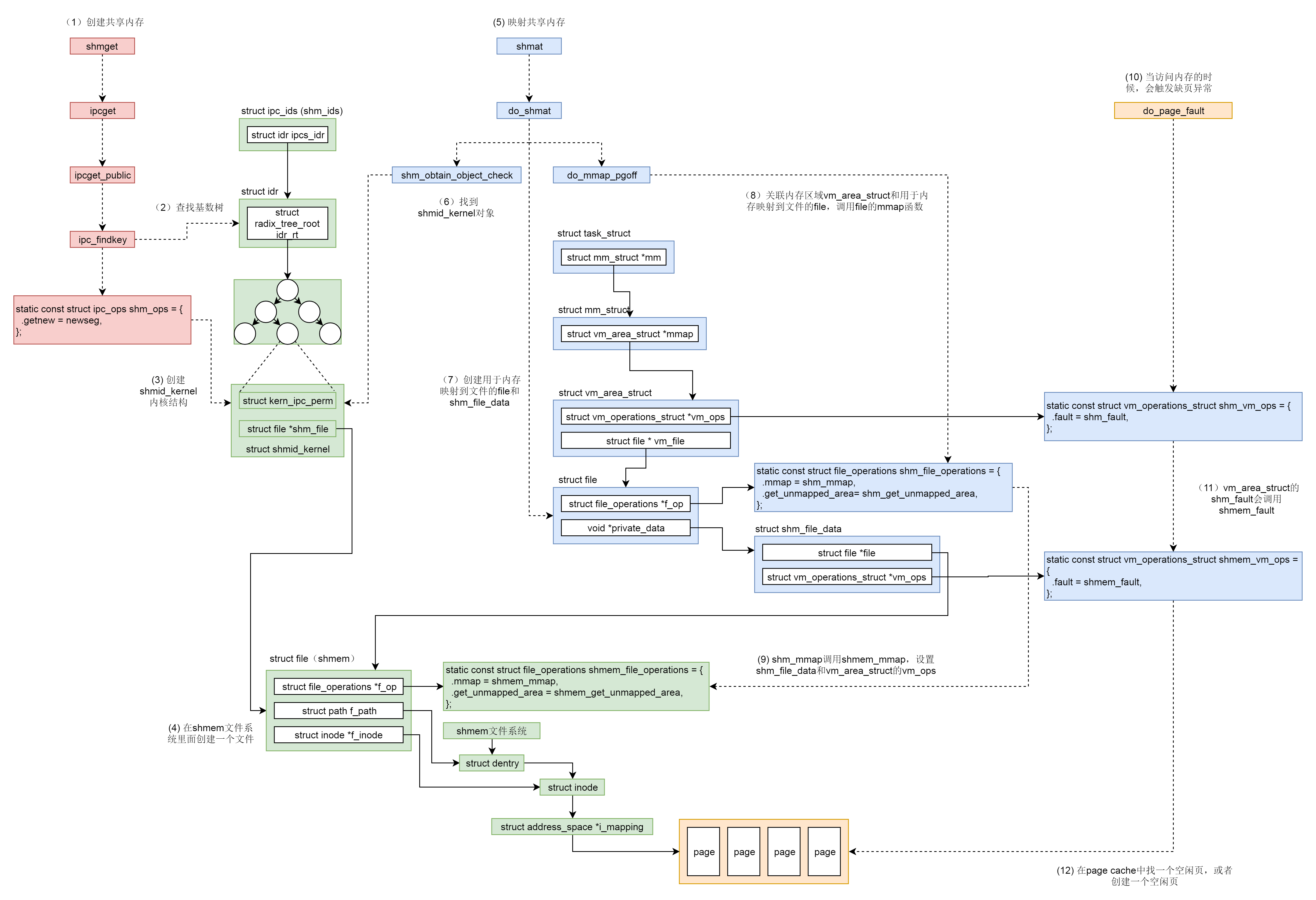
网络系统
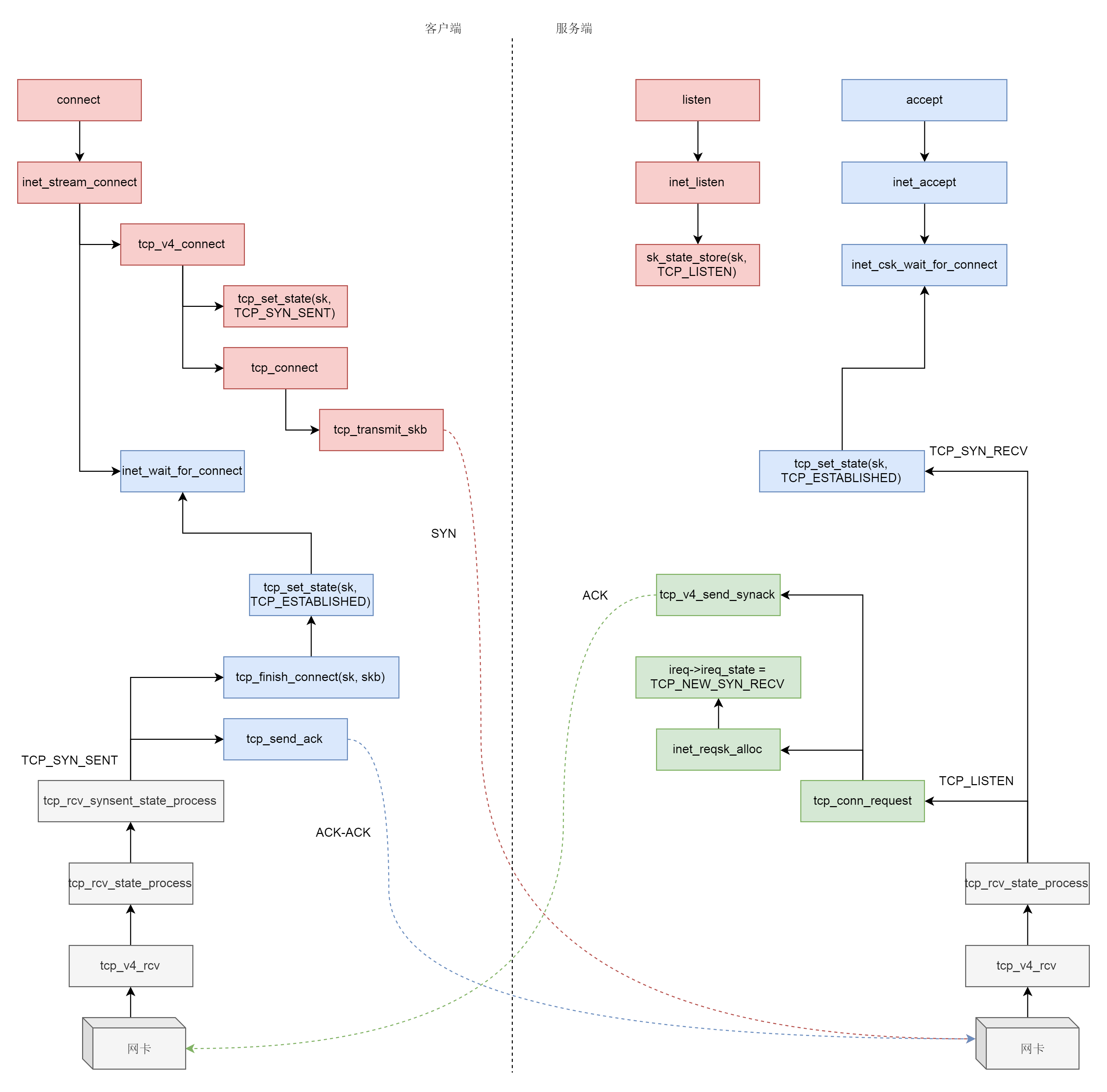
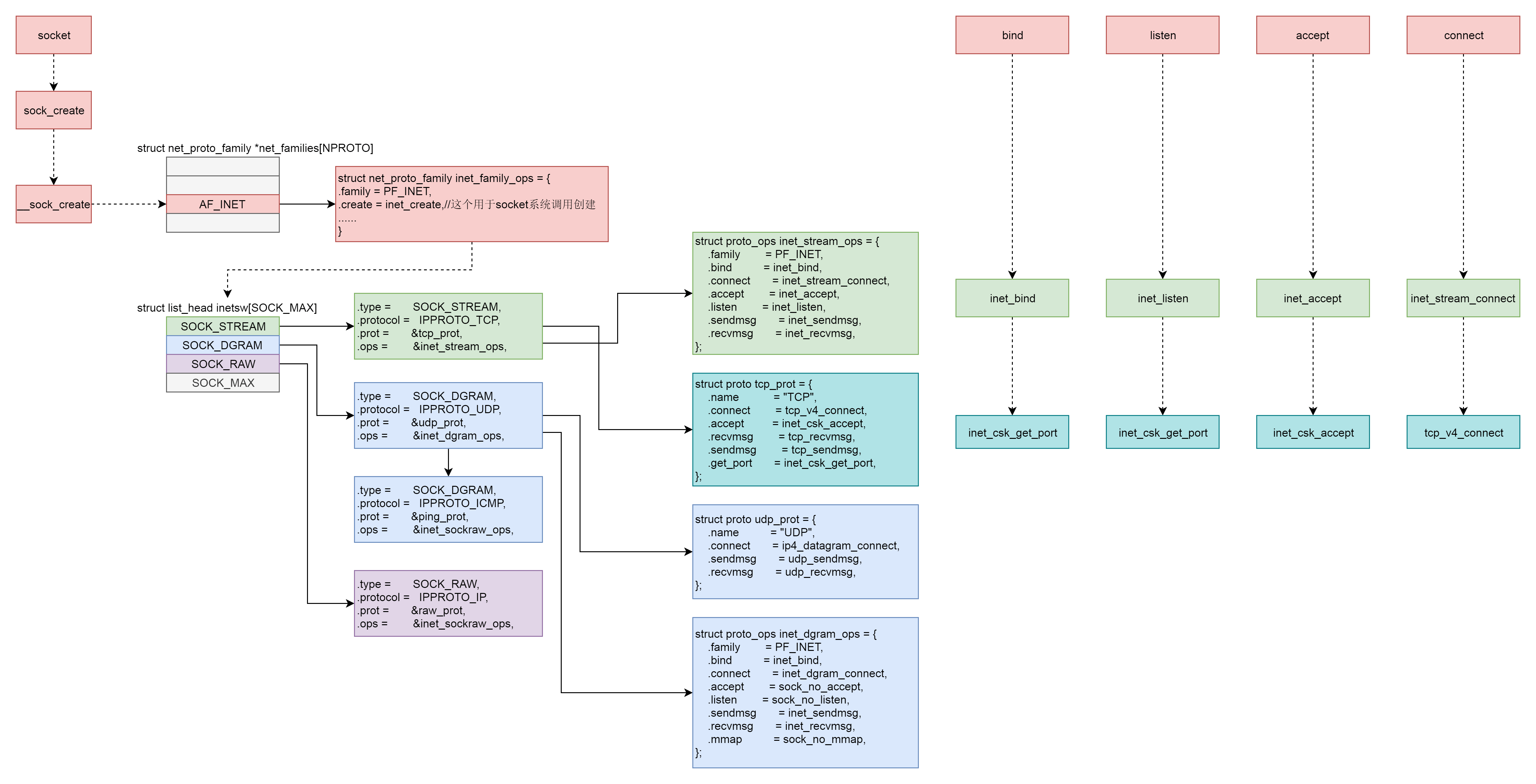
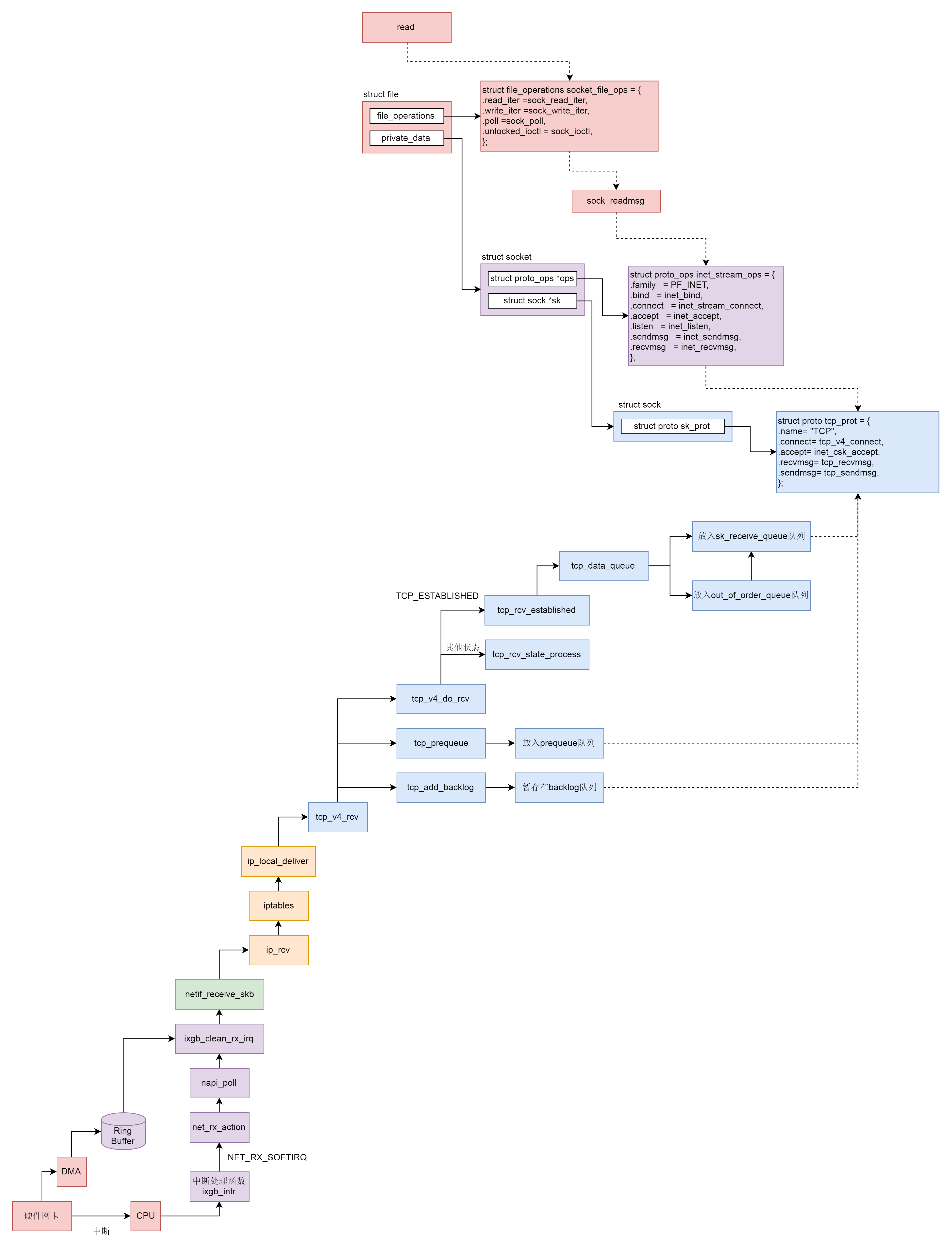
socket
一些关于socket的系统调用:
- 服务端和客户端都调用 socket,得到文件描述符
- 服务端调用 listen,进行监听
- 服务端调用 accept,等待客户端连接
- 客户端调用 connect,连接服务端
- 服务端 accept 返回用于传输的 socket 的文件描述符
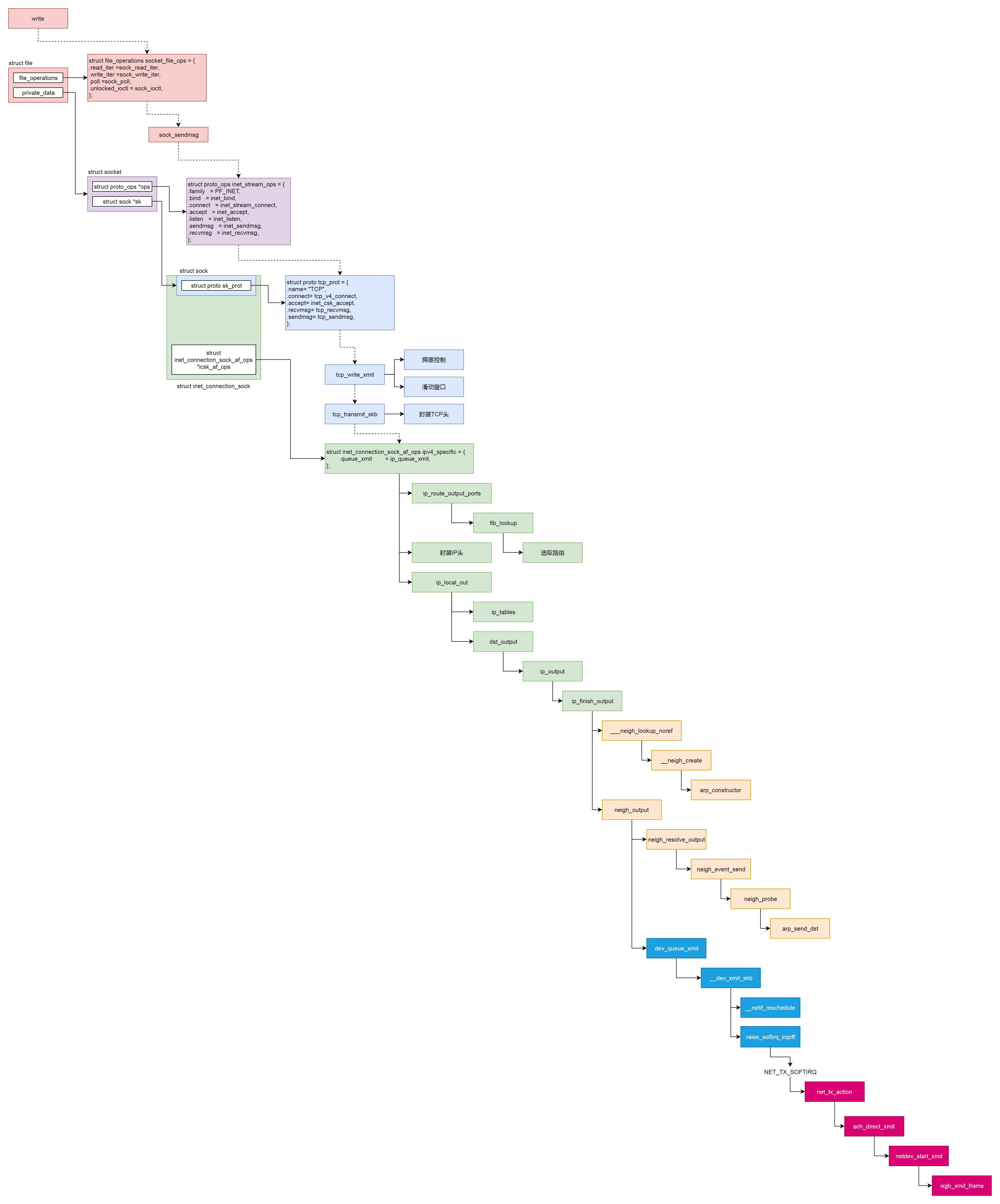
- 客户端调用 write 写入数据
- 服务端调用 read 读取数据。
在创建socket时,有三个参数:
- family:地址族,不是所有的 Socket 都要通过 IP 进行通信,还有其他的通信方式
- AF_UNIX Unix domain sockets
- AF_INET Internet IP Protocol
- type
- SOCK_STREAM 面向数据流的,协议 IPPROTO_TCP 属于这种类型
- SOCK_DGRAM 面向数据报的,协议 IPPROTO_UDP、IPPROTO_ICMP 属于这种类型
- SOCK_RAW 原始的 IP 包,IPPROTO_IP 属于这种类型
有一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询 poll 网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,称为 NAPI
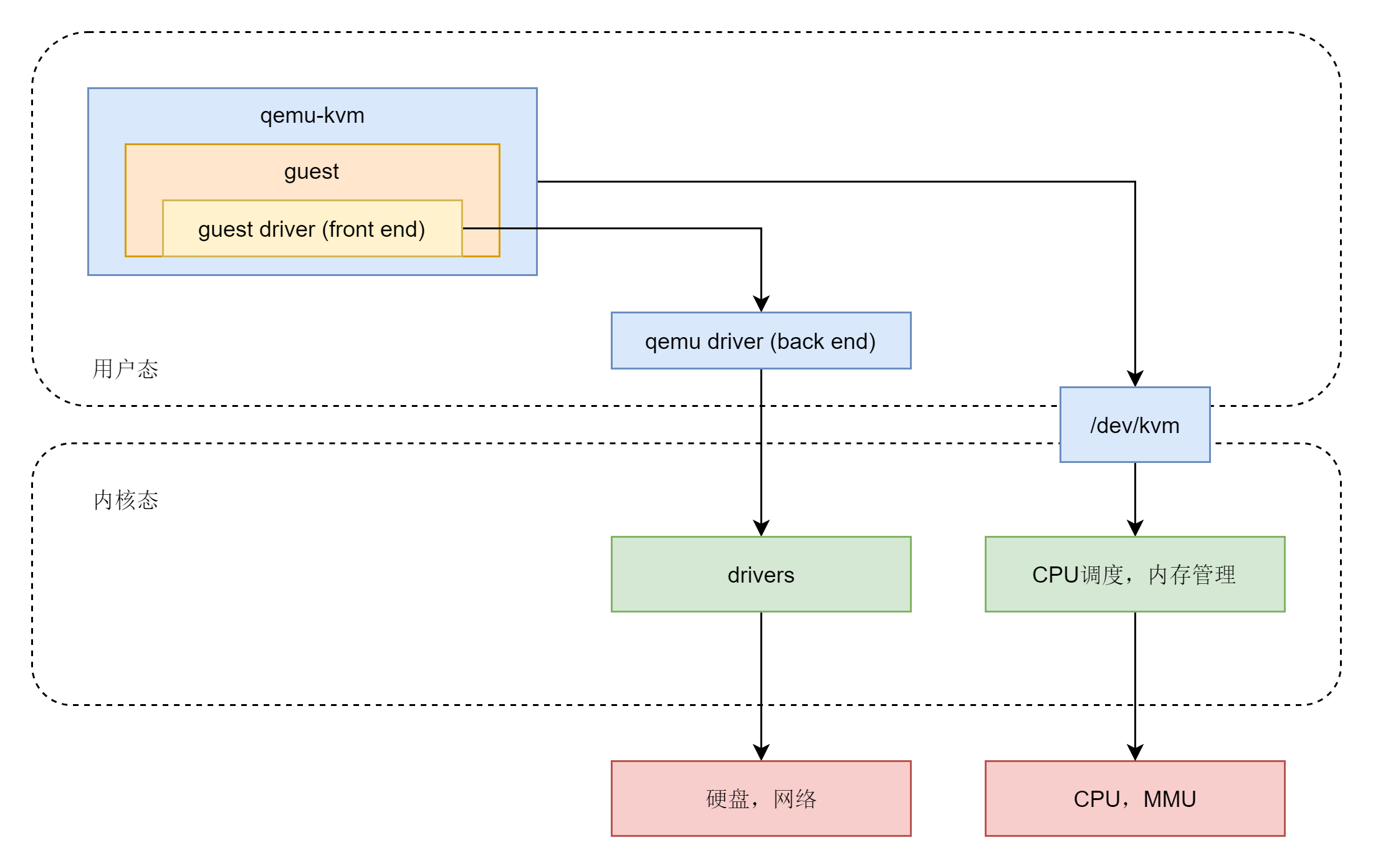
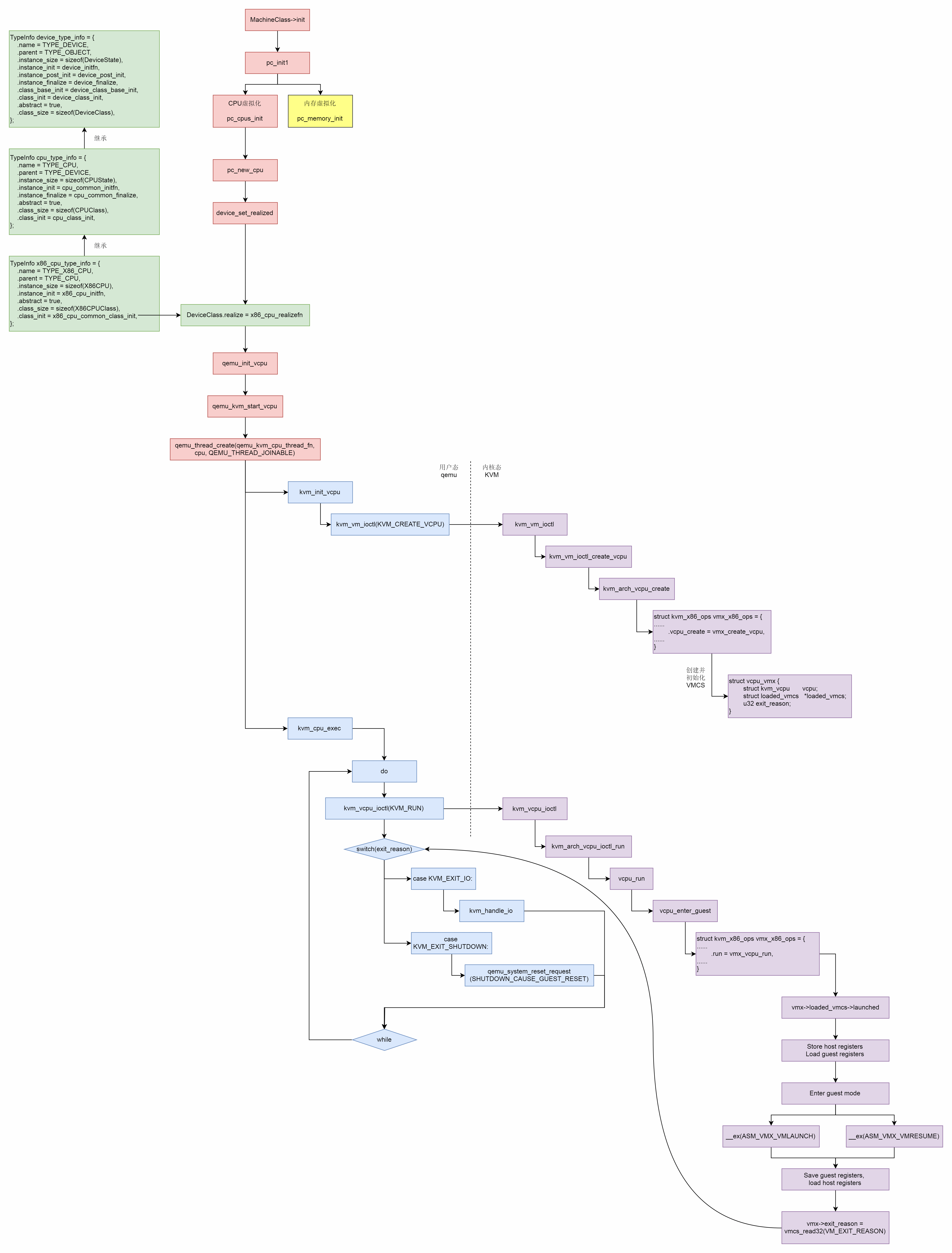
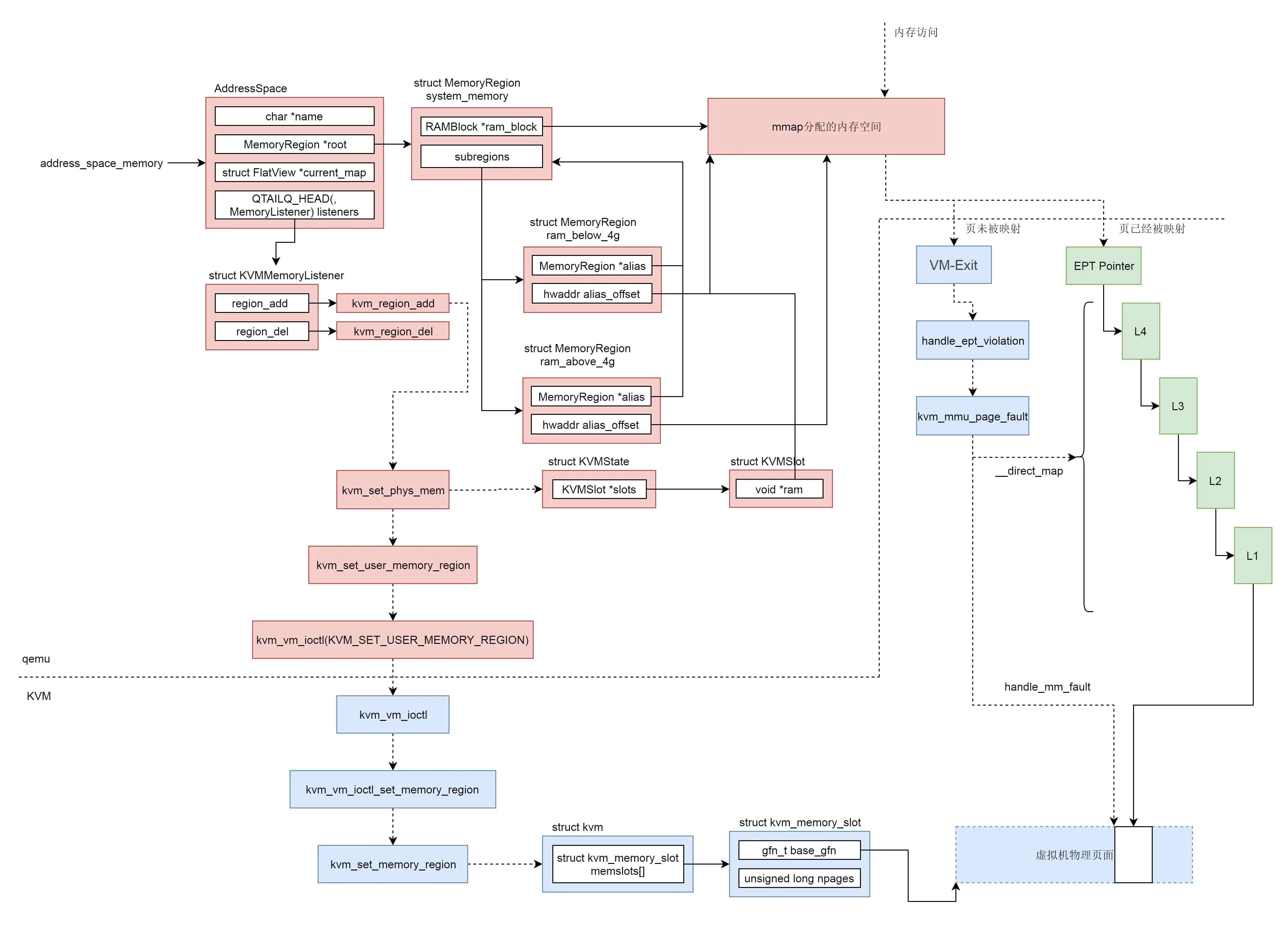
虚拟化
- 完全虚拟化
- 硬件辅助虚拟化:大部分指令直接在CPU上执行,少部分指令让物理机转述执行
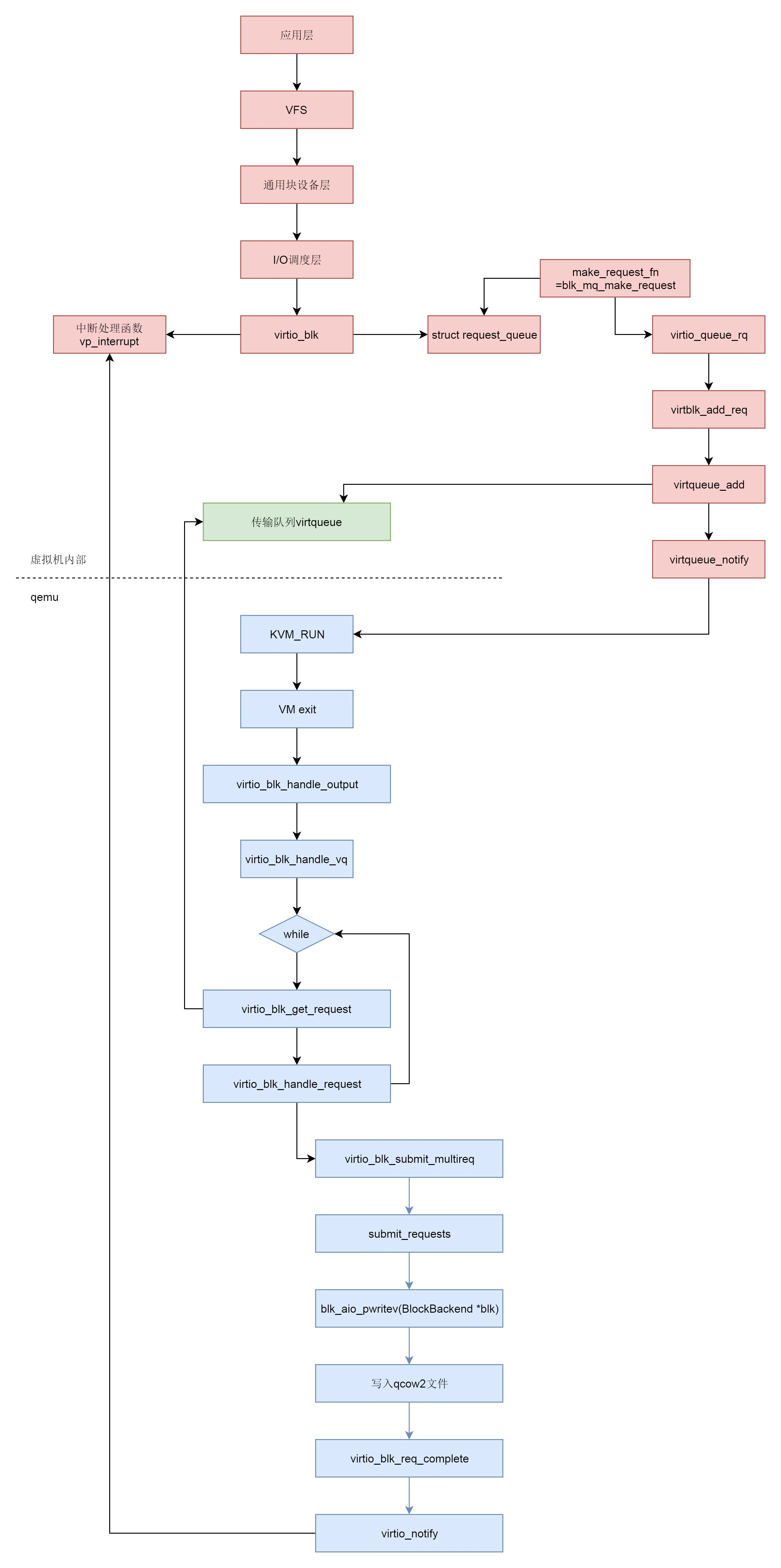
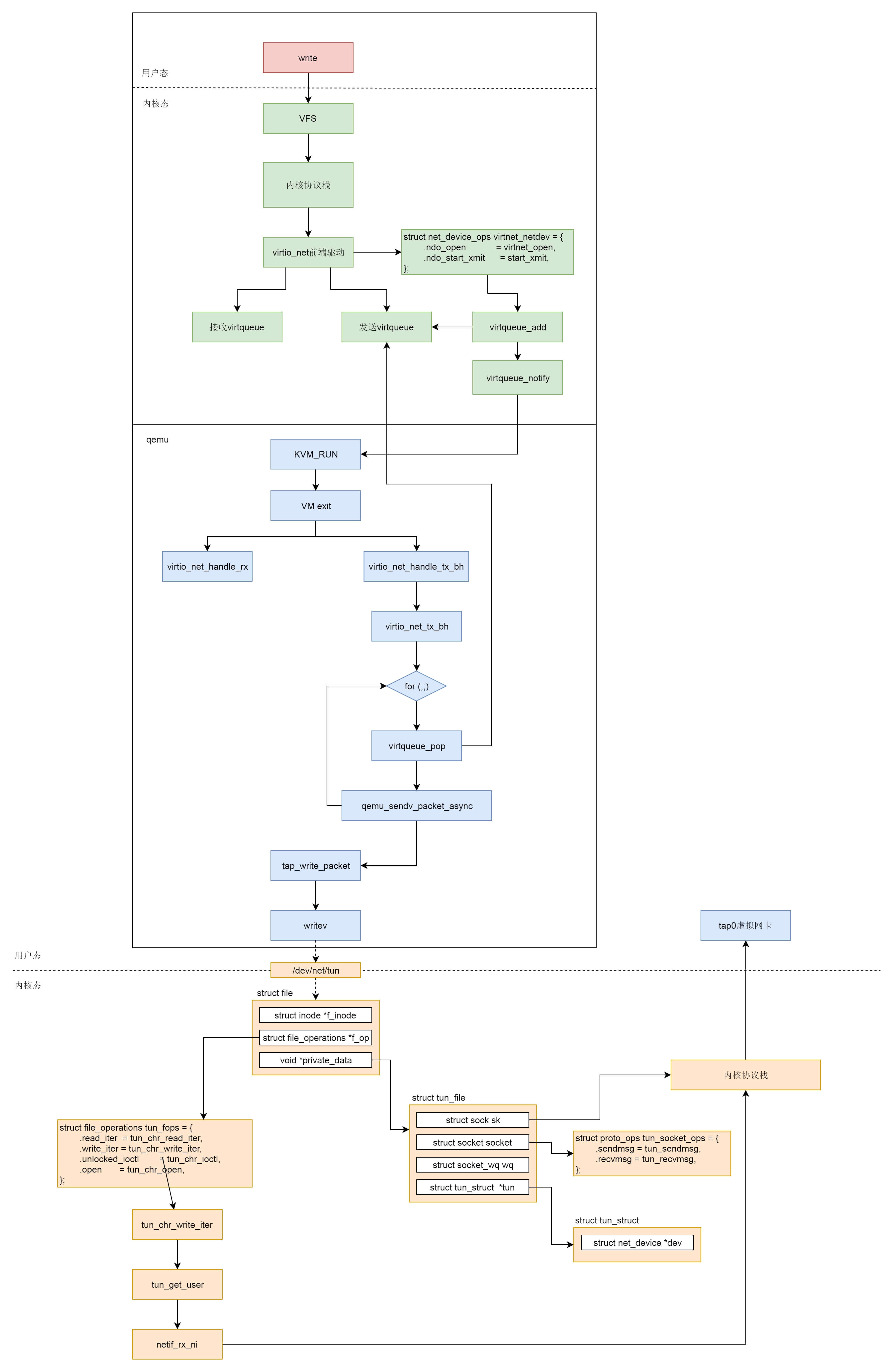
- 半虚拟化:通过加载驱动,GuestOS 知道自己是虚拟机,所以数据会直接发送给半虚拟化设备,经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件
容器化
namespace
为了隔离不同类型的资源,Linux 内核里面实现了以下几种不同类型的 namespace:
- UTS,对应的宏为 CLONE_NEWUTS,表示不同的 namespace 可以配置不同的 hostname
- User,对应的宏为 CLONE_NEWUSER,表示不同的 namespace 可以配置不同的用户和组
- Mount,对应的宏为 CLONE_NEWNS,表示不同的 namespace 的文件系统挂载点是隔离的
- PID,对应的宏为 CLONE_NEWPID,表示不同的 namespace 有完全独立的 pid,也即一个 namespace 的进程和另一个 namespace 的进程,pid 可以是一样的,但是代表不同的进程
- Network,对应的宏为 CLONE_NEWNET,表示不同的 namespace 有独立的网络协议栈
# 离开当前的 namespace,创建且加入新的 namespace,然后执行参数中指定的命令
unshare --mount --ipc --pid --net --mount-proc=/proc --fork /bin/bash
还可以通过函数操作 namespace:
// 创建一个新的进程,并把它放到新的 namespace 中
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
// 用于将当前进程加入到已有的 namespace 中
int setns(int fd, int nstype);
// 使当前进程退出当前的 namespace,并加入到新创建的 namespace
int unshare(int flags);
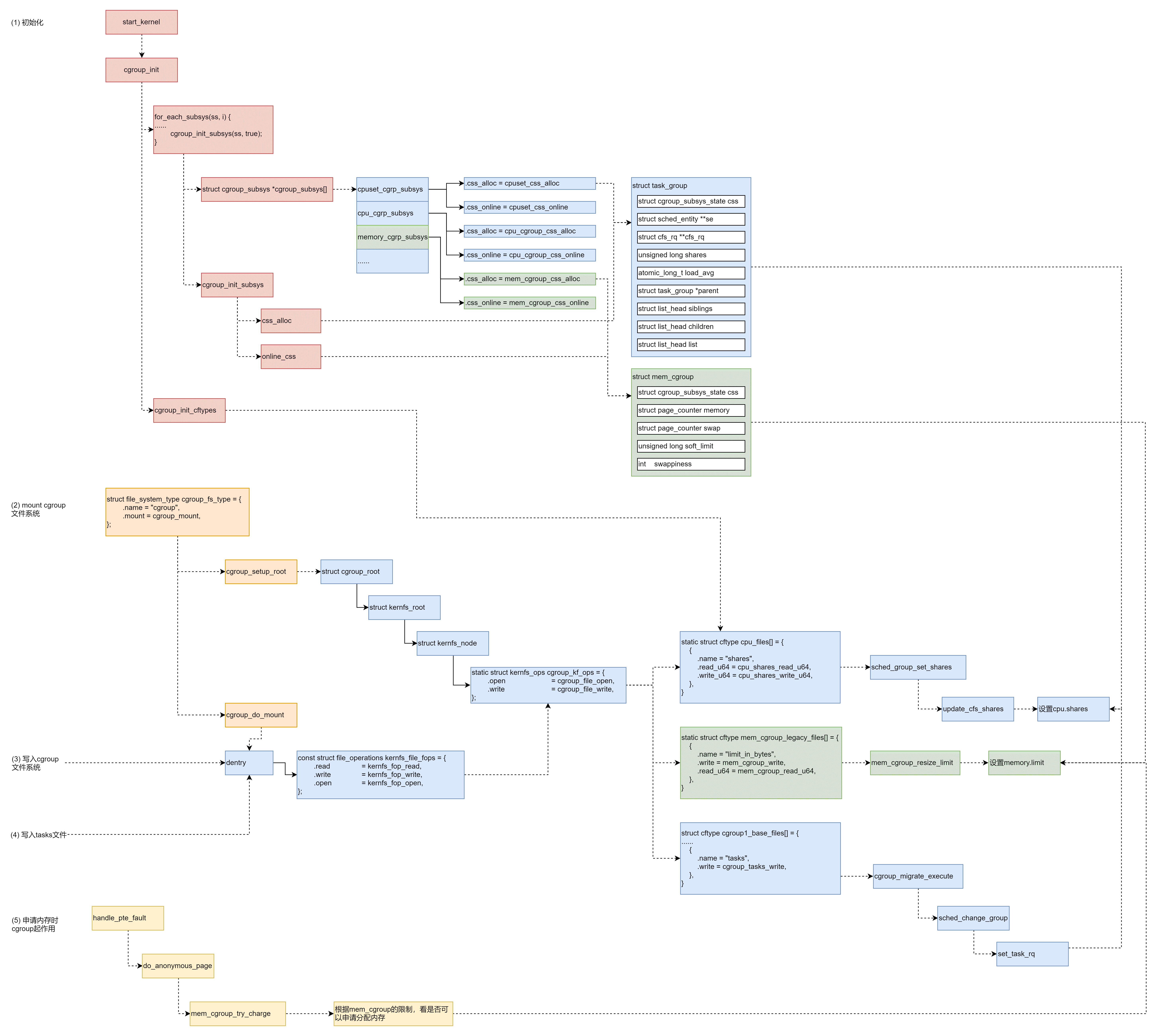
cgroup
定义了下面的一系列子系统,每个子系统用于控制某一类资源,本质上就是一系列配置,在内核运行的各个节点可以被读取,从而进行限制
- CPU 子系统,主要限制进程的 CPU 使用率
- cpuacct 子系统,可以统计 cgroup 中的进程的 CPU 使用报告
- cpuset 子系统,可以为 cgroup 中的进程分配单独的 CPU 节点或者内存节点
- memory 子系统,可以限制进程的 Memory 使用量
- blkio 子系统,可以限制进程的块设备 IO
- devices 子系统,可以控制进程能够访问某些设备
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制
- freezer 子系统,可以挂起或者恢复 cgroup 中的进程