服务容错
容错性设计不能妥协源于分布式系统的本质是不可靠的
容错:在错误发生时,系统依然可以提供正确的功能的能力,直接关系到可用性、可靠性
错误带来的一些问题
雪崩效应
基础服务的故障可能会导致级联故障, 进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程
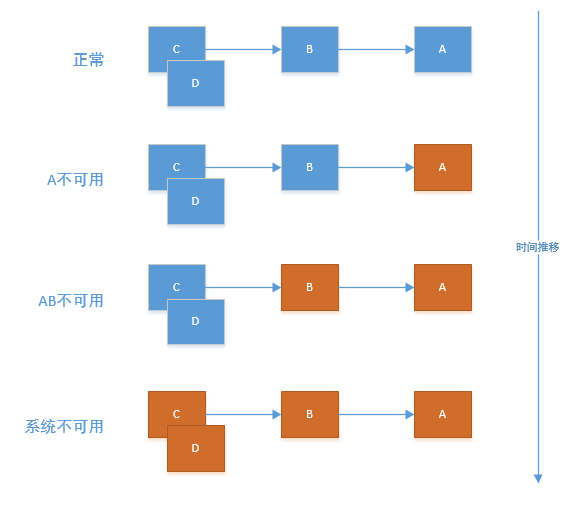
请求堆积
在大量请求到来时,处理器有一个线程池来处理请求,当请求到达量远远大于处理量,请求就会在线程池中堆积,从而导致大量请求被阻塞
容错策略
面对故障,我们该做些什么(空间冗余(副本机制)、时间冗余(重试机制))
- 故障转移(Failover):当对某些服务的调用失败 转而调用该服务的其他副本
- 这种重试策略应该要有一定的阈值 过度的重试反而可能让系统处于更加不利的状况
- 快速失败(Failfast):对于非幂等的服务调用失败 就应该直接使用失败而非重试来解决
- 安全失败(Failsafe):对于不在链路主线的服务调用 如日志 扩展点等 这些服务的结果不参与最终运算 即使失败了 也可以当做正确来返回
- 沉默失败(Failsilent):如果对于某个服务的调用大量超时失败 此时就很容易请求堆积而消耗资源 可以在一段时间内不再向它分配流量 类似于熔断
- 故障恢复(Failback):指当服务调用出错了以后,将该次调用失败的信息存入一个消息队列中,然后由系统自动开始异步重试调用
- 这种类型适合幂等调用的且没有返回值的链路主线服务调用
- 并行调用(Forking):一开始就同时向多个服务副本发起调用,只要有其中任何一个返回成功,那调用便宣告成功
- 广播调用(Broadcast):要求所有的请求全部都成功,这次调用才算是成功
| 容错策略 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 故障转移 | 系统自动处理,调用者对失败的信息不可见 | 增加调用时间,额外的资源开销 | 调用幂等服务,对调用时间不敏感的场景 |
| 快速失败 | 调用者有对失败的处理完全控制权,不依赖服务的幂等性 | 调用者必须正确处理失败逻辑,如果一味只是对外抛异常,容易引起雪崩 | 调用非幂等的服务 |
| 安全失败 | 不影响主路逻辑 | 只适用于旁路调用 | 调用链中的旁路服务 |
| 沉默失败 | 控制错误不影响全局 | 出错的地方将在一段时间类不可用 | 频繁超时的服务 |
| 故障恢复 | 调用失败后自动重试,也不影响主路逻辑 | 推荐用于旁路服务调用,或者对实时性要求不高的主路逻辑,重试任务可能产生堆积,重试仍然可能失败 | 调用链中的旁路服务,对实时性要求不高的主路逻辑也可以使用 |
| 并行调用 | 尽可能在最短时间内获得最高的成功率 | 额外消耗机器资源,大部分调用可能都是无用功 | 资源充足且对失败容忍度低的场景 |
| 广播调用 | 支持同时对批量的服务提供者发起调用 | 资源消耗大,失败概率高 | 只适用于批量操作的场景 |
容错设计模式
断路器模式
通过代理(断路器对象)来一对一地(一个远程服务对应一个断路器对象)地接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它状态就自动变为“OPEN”,后续此断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求
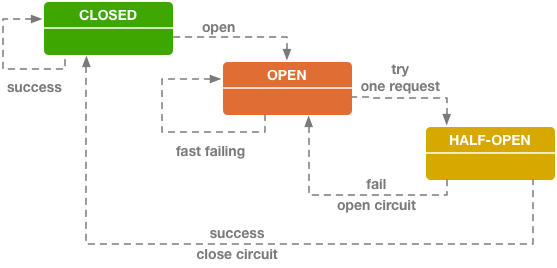
现实中,当以下两个条件同时满足 断路器就会打开:
- 一段时间内请求达到某个阈值
- 一段时间内请求的故障率达到某个阈值
舱壁隔离模式
当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其它模块,不影响整体的系统服务
无论是使用线程池或者信号量来隔离 本质上都是为了将故障隔离到最小的粒度 防止扩散
服务分组
对于拥有许多节点的服务提供者,可以进行打标签给不同的调用者使用,进行分组隔离,避免公用相同的提供者降低雪崩的风险,不过这一般在容器调度里才比较常用
基于动态分组的隔离,可以在某个分组流量激增时,快速借用留有富余的分组的节点从而度过流量高峰,相比动态扩缩容,见效更快
重试模式
重试时 应该同时满足以下几个条件:
- 仅对链路主线的关键服务进行同步重试
- 进队瞬时故障进行重试 像类似403 404这种错误重试没有意义
- 仅对幂等调用进行重试
- 重试要有终止条件
- 重试次数
- 超时终止
优雅上下线
下线
当进入关闭流程时,已经进来的请求可以慢慢处理完,对于新来的请求,直接提示本服务正在关闭拒绝掉,当所有请求处理完,则可以进行关闭
上线
- 启动预热:对于刚启动的服务,给其的调用权重不要那么高,这样可以避免一启动就有大流量打进来
- 延迟暴露:只有服务提供方完全追备好了,才向注册中心注册
Hystrix
当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN).
这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN)
统计器(Metrics):滑动窗口(metrics.rollingStats.timeInMilliseconds)以及桶(metrics.rollingStats.numBuckets)
Hystrix 并不是只要有一条请求经过就去统计,而是将整个滑动窗口均分为 numBuckets 份,时间每经过一份就去统计一次。在经过一个时间窗口后,才会判断断路器状态要不要开启
在Hystrix中, 主要通过线程池来实现资源隔离. 添加 @HystrixCommand 这个注解之后,hystrix会开启服务隔离,访问这个接口的线程独属于某一个线程池。通常在使用的时候我们会根据调用的远程服务划分出多个线程池 每个外部依赖用一个单独的线程池,这样的话,如果对那个外部依赖调用延迟很严重,最多就是耗尽那个依赖自己的线程池而已,不会影响其他的依赖调用
线程池机制的缺点:多了一些管理线程,增加了CPU的开销
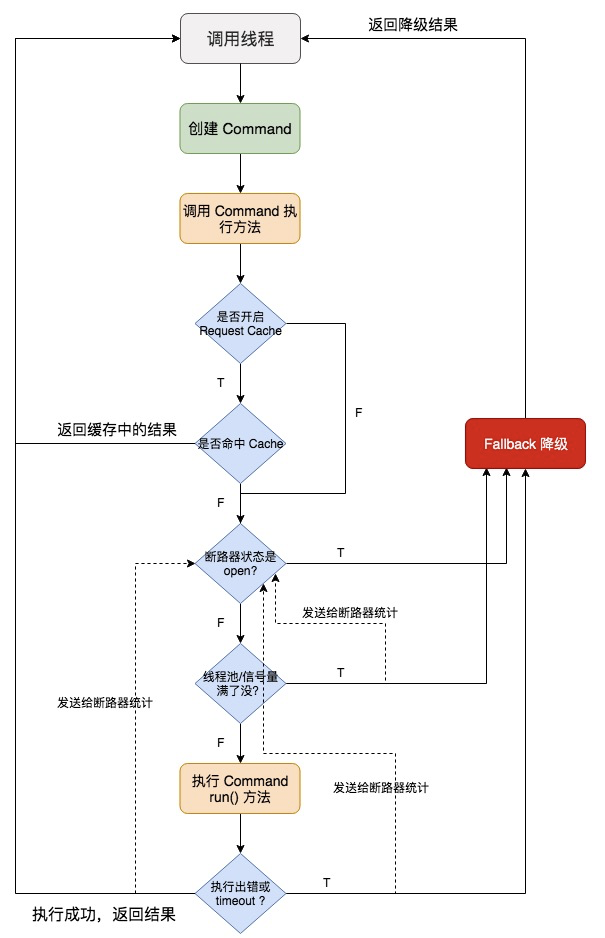
一些概念:
- command key 代表了一类 command,一般来说,代表了下游依赖服务的某个接口
- command group 默认情况下,就是通过 command group 来定义一个线程池的,而且还会通过 command group 来聚合一些监控和报警信息,同一个 command group 中的请求,都会进入同一个线程池中
Sentinel
基本概念
- 资源:可以是 Java 应用程序中的任何内容
- 规则:包括流量控制规则、熔断降级规则以及系统保护规则
流量控制:Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状
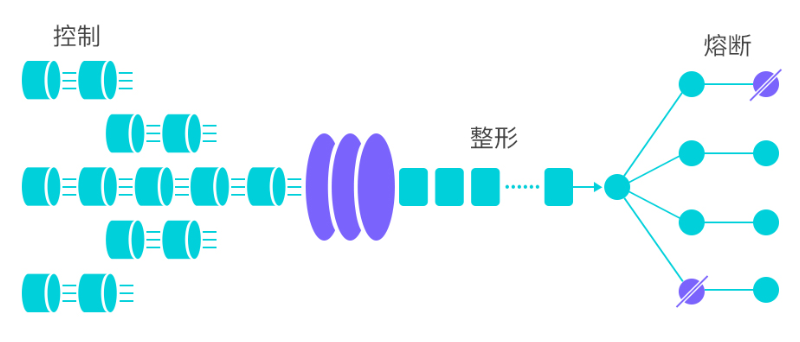
流量控制可以从以下角度切入:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系
- 运行指标,例如 QPS、线程池、系统负载等
- 控制的效果,例如直接限流、冷启动、排队等
sentinel 通过使用以下方式熔断降级:
- 并发线程数 同计数器 当线程数达到一定数量 新的请求就会被拒绝
- 响应时间 当资源响应时间超过阈值 对该资源的访问会直接拒绝
基本原理
所有的资源都对应一个资源名称以及一个 Entry。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 API 显式创建
通过一系列的Slot来实现相对应的功能
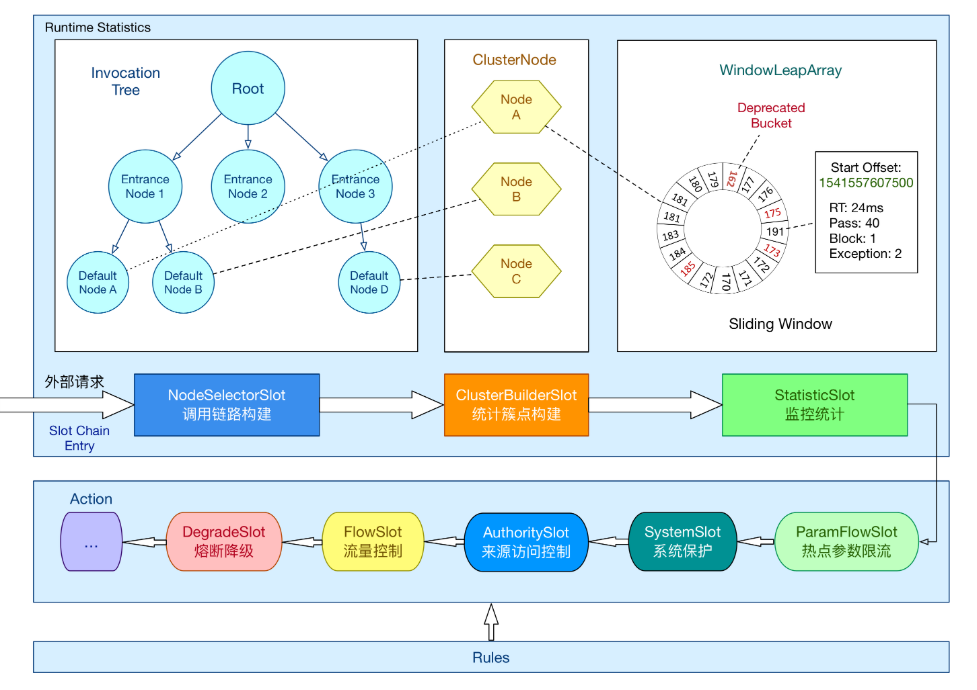
vs hystrix
| item | Sentinel | Hystrix |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于响应时间或失败比率 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速器模式 | 不支持 |
| 系统负载保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |