p3c
现代软件架构的复杂性需要协同开发完成,如何高效地协同呢?无规矩不成方圆,无规范难以协同
编码
命名
- 【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束
- 【强制】代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式 一个好的命名应该是望文生义
- 【强制】类名使用 UpperCamelCase 风格,但以下情形例外:DO / BO / DTO / VO / AO / PO / UID 等
- 【强制】方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格
- 【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长
- 【强制】抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类命名以它要测试的类的名称开始,以 Test 结尾
- 【强制】类型与中括号紧挨相连来表示数组
- 【强制】POJO 类中布尔类型变量都不要加 is 前缀,否则部分框架解析会引起序列化错误 这条与数据库字段名需要以is开头起冲突了 需要通过手动映射的方式来将is_xx 映射到 xx
- 【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式
- 【强制】避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名,使可读性降低 只有方法才会多态 属性访问并不会
- 【强制】杜绝完全不规范的缩写 将AbtractFactory 缩写成 AbsFac 可能不是一个好主意
- 【推荐】为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组合来表达其意
- 【推荐】在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度
- 【推荐】如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式
- 【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁性,并加上有效的 Javadoc 注释
- 【推荐】尽量不要在接口里定义变量,如果一定要定义变量,肯定是与接口方法相关,并且是整个应用的基础常量 可以是接口的基础常量
- 【强制】对于 Service 和 DAO 类,基于 SOA 的理念,暴露出来的服务一定是接口,内部的实现类用Impl 的后缀与接口区别 既然是基于SOA的理念 那么现在大部分都是内部调用的Service就没必要定义接口了
- 【推荐】如果是形容能力的接口名称,取对应的形容词为接口名(通常是–able 的形容词)
- 【参考】枚举类名带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开
- 【参考】各层命名规范
- Service/DAO
- 获取单个对象的方法用 get 做前缀。
- 获取多个对象的方法用 list 做前缀,复数形式结尾如:listObjects。
- 获取统计值的方法用 count 做前缀。
- 插入的方法用 save/insert 做前缀。
- 删除的方法用 remove/delete 做前缀。
- 修改的方法用 update 做前缀
- 领域模型
- 数据对象:xxxDO,xxx 即为数据表名。
- 数据传输对象:xxxDTO,xxx 为业务领域相关的名称。
- 展示对象:xxxVO,xxx 一般为网页名称。
- POJO 是 DO/DTO/BO/VO 的统称,禁止命名成 xxxPOJO。
- Service/DAO
常量定义
【强制】不允许任何魔法值直接出现在代码中
【强制】在 long 或者 Long 赋值时,数值后使用大写的 L,不能是小写的 l,小写容易跟数字 1 混淆,造成误解
【推荐】不要使用一个常量类维护所有常量,要按常量功能进行归类,分开维护
【推荐】常量的复用层次有五层:
- 跨应用共享常量:其他库中
- 应用内共享常量:本工程子模块中
- 子工程内共享常量:本工程中的const目录
- 包内共享常量:本包的const目录
- 类内共享常量:使用private static final定义
【推荐】如果变量值仅在一个固定范围内变化用 enum 类型来定义
代码格式
- 【强制】如果是大括号内为空,则简洁地写成{}即可,大括号中间无需换行和空格,否则:
- 左大括号前不换行。
- 左大括号后换行。
- 右大括号前换行。
- 右大括号后还有 else 等代码则不换行;表示终止的右大括号后必须换行。
- 【强制】左小括号和字符之间不出现空格 ; 同样,右小括号和字符之间也不出现空格;而左大括号前需要空格
- 【强制】if/for/while/switch/do 等保留字与括号之间都必须加空格
- 【强制】任何二目、三目运算符的左右两边都需要加一个空格
- 【强制】采用 4 个空格缩进,禁止使用 tab 字符
- 【强制】注释的双斜线与注释内容之间有且仅有一个空格
- 【强制】在进行类型强制转换时,右括号与强制转换值之间不需要任何空格隔开
- 【强制】单行字符数限制不超过 120 个,超出需要换行,换行时遵循如下原则:
- 第二行相对第一行缩进 4 个空格,从第三行开始,不再继续缩进。
- 运算符与下文一起换行。
- 方法调用的点符号与下文一起换行。
- 方法调用中的多个参数需要换行时,在逗号后进行。
- 在括号前不要换行,见反例
- 【强制】方法参数在定义和传入时,多个参数逗号后边必须加空格
- 【强制】IDE 的 text file encoding 设置为 UTF-8; IDE 中文件的换行符使用 Unix 格式
- 【推荐】单个方法的总行数不超过 80 行
- 【推荐】没有必要增加若干空格来使变量的赋值等号与上一行对应位置的等号对齐
- 【推荐】不同逻辑、不同语义、不同业务的代码之间插入一个空行分隔开来以提升可读性
OOP规约
- 【强制】避免通过一个类的对象引用访问此类的静态变量或静态方法,无谓增加编译器解析成本,直接用类名来访问即可
- 【强制】所有的覆写方法,必须加@ Override 注解
- 【强制】相同参数类型,相同业务含义,才可以使用 Java 的可变参数,避免使用 Object...
- 【强制】外部正在调用或者二方库依赖的接口,不允许修改方法签名,避免对接口调用方产生影响。接口过时必须加@ Deprecated 注解,并清晰地说明采用的新接口或者新服务是什么
- 【强制】不能使用过时的类或方法
- 【强制】 Object 的 equals 方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals
- 【强制】 任何货币金额,均以最小货币单位且整型类型来进行存储
- 【强制】所有整型包装类对象之间值的比较,全部使用 equals 方法比较
- 【强制】浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用equals 来判断
- 【强制】定义数据对象 DO 类时,属性类型要与数据库字段类型相匹配
- 【强制】为了防止精度损失,禁止使用构造方法 BigDecimal(double) 的方式把 double 值转化为 BigDecimal 对象,优先使用入参的 String 构造函数
- 【强制】由于自动装箱拆箱的原因,所有的 POJO 类属性必须使用包装数据类型
- 【强制】RPC 方法的返回值和参数必须使用包装数据类型
- 【推荐】所有的局部变量使用基本数据类型
- 【强制】定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值
- 【强制】序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值
- 【强制】构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在 init 方法中
- 【强制】POJO 类必须写 toString 方法。使用 IDE 中的工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString
- 【强制】禁止在 POJO 类中,同时存在对应属性 xxx 的 isXxx()和 getXxx()方法
- 【推荐】使用索引访问用 String 的 split 方法得到的数组时,需做最后一个分隔符后有无内容的检查,如果最后一个分隔符并没有内容,那么并不会产生一个空字符串
- 【推荐】当一个类有多个构造方法,或者多个同名方法,这些方法应该按顺序放置在一起,便于阅读
- 【推荐】类内方法定义的顺序依次是:公有方法或保护方法 > 私有方法 > getter / setter方法,此条规则规则的优先级低于上一条
- 【推荐】setter 方法中,参数名称与类成员变量名称一致,this.成员名 = 参数名。在getter/setter 方法中,不要增加业务逻辑,会增加排查问题的难度
- 【推荐】循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行替代
- 【推荐】慎用 Object 的 clone 方法来拷贝对象,该方法默认为浅拷贝
- 【推荐】类成员与方法访问控制从严
日期时间
- 【强制】日期格式化时,传入 pattern 中表示年份统一使用小写的 y
- 【强制】在日期格式中分清楚大写的 M 和小写的 m,大写的 H 和小写的 h 分别指代的意义
- 表示月份是大写的 M;
- 表示分钟则是小写的 m;
- 24 小时制的是大写的 H;
- 12 小时制的则是小写的 h
- 【强制】获取当前毫秒数:System.currentTimeMillis(); 而不是 new Date().getTime() JDK8以上可以使用 Instant
- 【强制】不允许在程序任何地方中使用:1)java.sql.Date。 2)java.sql.Time。3)java.sql.Timestamp
- 【强制】不要在程序中写死一年为 365 天
- 【推荐】避免公历闰年 2 月问题。闰年的 2 月份有 29 天,一年后的那一天不可能是 2 月 29日
- 【推荐】使用枚举值来指代月份。如果使用数字,注意 Date,Calendar 等日期相关类的月份month 取值在 0-11 之间
集合处理
- 【强制】关于 hashCode 和 equals 的处理,遵循如下规则
- 只要覆写 equals,就必须覆写 hashCode。
- 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须覆 写这两个方法。
- 如果自定义对象作为 Map 的键,那么必须覆写 hashCode 和 equals。
- 【强制】判断所有集合内部的元素是否为空,使用 isEmpty()方法,而不是 size()==0 的方式
- 【强制】在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要使用含有参数类型为 BinaryOperator,参数名为 mergeFunction 的方法,否则当出现相同 key值时会抛出 IllegalStateException 异常
- 【强制】在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要注意当 value 为 null 时会抛 NPE 异常
- 【强制】ArrayList 的 subList 结果不可强转成 ArrayList subList返回的是原来List的一个映射 在subList上所做的修改都会反映到原List
- 【强制】使用 Map 的方法 keySet() / values() / entrySet() 返回集合对象时,不可以对其进行添加元素操作,否则会抛出 UnsupportedOperationException 异常
- 【强制】Collections 类返回的对象,如: emptyList() / singletonList() 等都是 immutablelist,不可对其进行添加或者删除元素的操作
- 【强制】在 subList 场景中,高度注意对原集合元素的增加或删除,均会导致子列表的遍历、增加、删除产生 ConcurrentModificationException 异常
- 【强制】使用集合转数组的方法,必须使用集合的 toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组
- 【强制】在使用 Collection 接口任何实现类的 addAll()方法时,都要对输入的集合参数进行NPE 判断
- 【强制】使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常
- 【强制】使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常
- 【强制】泛型通配符 <? extends T> 来接收返回的数据,此写法的泛型集合不能使用 add 方法,而 <? super T> 不能使用 get 方法
- 【强制】在无泛型限制定义的集合赋值给泛型限制的集合时,在使用集合元素时,需要进行instanceof 判断,避免抛出 ClassCastException 异常
- 【强制】不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用Iterator 方式,如果并发操作,需要对 Iterator 对象加锁
- 【强制】在 JDK 7 版本及以上, Comparator 实现类要满足对称性与传递性,不然 Arrays.sort ,Collections.sort 会抛 IllegalArgumentException 异常
- 【推荐】集合泛型定义时,在 JDK7 及以上,使用 diamond 语法或全省略
- 【推荐】集合初始化时,指定集合初始值大小
- 【推荐】使用 entrySet 遍历 Map 类集合 KV ,而不是 keySet 方式进行遍历
- 【推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况
- 【参考】合理利用好集合的有序性(sort)和稳定性(order),避免集合的无序性(unsort)和不稳定性(unorder)带来的负面影响
- 【参考】利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作
并发处理
- 【强制】获取单例对象需要保证线程安全,其中的方法也要保证线程安全
- 【强制】创建线程或线程池时请指定有意义的线程名称,方便出错时回溯
- 【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程
- 【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
- 【强制】SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为static ,必须加锁,或者使用 DateUtils 工具类
- 【强制】必须回收自定义的 ThreadLocal 变量,尤其在线程池场景下,线程经常会被复用,如果不清理自定义的 ThreadLocal 变量,可能会影响后续业务逻辑和造成内存泄露等问题。尽量在代理中使用 try-finally 块进行回收
- 【强制】高并发时,同步调用应该去考量锁的性能损耗。能用无锁数据结构,就不要用锁 ;能锁区块,就不要锁整个方法体 ; 能用对象锁,就不要用类锁
- 【强制】对多个资源、数据库表、对象同时加锁时,需要保持一致的加锁顺序,否则可能会造成死锁
- 【强制】在使用阻塞等待获取锁的方式中,必须在 try 代码块之外,并且在加锁方法与 try 代码块之间没有任何可能抛出异常的方法调用,避免加锁成功后,在 finally 中无法解锁
- 【强制】在使用尝试机制来获取锁的方式中,进入业务代码块之前,必须先判断当前线程是否持有锁
- 【强制】并发修改同一记录时,避免更新丢失,需要加锁。要么在应用层加锁,要么在缓存加锁,要么在数据库层使用乐观锁,使用 version 作为更新依据
- 【强制】多线程并行处理定时任务时, Timer 运行多个 TimeTask 时,只要其中之一没有捕获抛出的异常,其它任务便会自动终止运行,如果在处理定时任务时使用ScheduledExecutorService 则没有这个问题
- 【推荐】资金相关的金融敏感信息,使用悲观锁策略
- 【推荐】使用 CountDownLatch 进行异步转同步操作,每个线程退出前必须调用 countDown 方法,线程执行代码注意 catch 异常,确保 countDown 方法被执行到,避免主线程无法执行至await 方法,直到超时才返回结果
- 【推荐】避免 Random 实例被多线程使用
- 【推荐】通过双重检查锁 (double - checked locking)在并发场景仍然会有问题 此时可以通过配合volatile关键字的方式解决
- 【参考】volatile无法解决线程安全问题
- 【参考】HashMap 在容量不够进行 resize 时由于高并发可能出现死链,导致 CPU 飙升,在开发过程中注意规避此风险
- 【参考】ThreadLocal 对象使用 static 修饰,ThreadLocal 无法解决共享对象的更新问题
控制语句
- 【强制】在一个 switch 块内,每个 case 要么通过 continue/break/return 等来终止,要么注释说明程序将继续执行到哪一个 case 为止;在一个 switch 块内,都必须包含一个 default
- 【强制】在一个 switch 块内,每个 case 要么通过 continue/break/return 等来终止,要么注释说明程序将继续执行到哪一个 case 为止;在一个 switch 块内,都必须包含一个 default
- 【强制】当 switch 括号内的变量类型为 String 并且此变量为外部参数时,必须先进行 null判断
- 【强制】在 if / else / for / while / do 语句中必须使用大括号
- 【强制】三目运算符 condition? 表达式 1 : 表达式 2 中,高度注意表达式 1 和 2 在类型对齐时,可能抛出因自动拆箱导致的 NPE 异常
- 【强制】在高并发场景中,避免使用”等于”判断作为中断或退出的条件
- 【推荐】当某个方法的代码总行数超过 10 行时,return / throw 等中断逻辑的右大括号后均需要加一个空行
- 【推荐】表达异常的分支时,少用 if-else 方式 ,这种方式可以用卫语句 策略模式 状态模式等实现
- 【推荐】除常用方法(如 getXxx/isXxx )等外,不要在条件判断中执行其它复杂的语句,将复杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性
- 【推荐】不要在其它表达式(尤其是条件表达式)中,插入赋值语句
- 【推荐】不循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、获取数据库连接,进行不必要的 try - catch 操作 ( 这个 try - catch 是否可以移至循环体外 )
- 【推荐】避免采用取反逻辑运算符
- 【推荐】公开接口需要进行入参保护,尤其是批量操作的接口
- 【参考】需要进行参数校验的情形
- 调用频次低的方法。
- 执行时间开销很大的方法。此情形中,参数校验时间几乎可以忽略不计,但如果因为参数错误导致中间执行回退,或者错误,那得不偿失。
- 需要极高稳定性和可用性的方法。
- 对外提供的开放接口,不管是 RPC/API/HTTP 接口。
- 敏感权限入口
- 【参考】不需要进行参数校验的情形
- 极有可能被循环调用的方法。但在方法说明里必须注明外部参数检查。
- 底层调用频度比较高的方法。毕竟是像纯净水过滤的最后一道,参数错误不太可能到底层才会暴露问题。一般 DAO 层与 Service 层都在同一个应用中,部署在同一台服务器中,所以 DAO 的参数校验,可以省略。
- 被声明成 private 只会被自己代码所调用的方法,如果能够确定调用方法的代码传入参数已经做过检查或者肯定不会有问题,此时可以不校验参数。
注释规约
- 【强制】类、类属性、类方法的注释必须使用 Javadoc 规范
- 【强制】所有的抽象方法 ( 包括接口中的方法 ) 必须要用 Javadoc 注释、除了返回值、参数、异常说明外,还必须指出该方法做什么事情,实现什么功能
- 【强制】所有的类都必须添加创建者和创建日期
- 【强制】方法内部单行注释,在被注释语句上方另起一行,使用//注释
- 【强制】所有的枚举类型字段必须要有注释,说明每个数据项的用途
- 【推荐】与其“半吊子”英文来注释,不如用中文注释把问题说清楚
- 【推荐】与其“半吊子”英文来注释,不如用中文注释把问题说清楚
- 【推荐】代码修改的同时,注释也要进行相应的修改,尤其是参数、返回值、异常、核心逻辑等的修改
- 【推荐】在类中删除未使用的任何字段、方法、内部类;在方法中删除未使用的任何参数声明与内部变量
- 【参考】谨慎注释掉代码。在上方详细说明,而不是简单地注释掉。如果无用,则删除
- 【参考】对于注释的要求:第一、能够准确反映设计思想和代码逻辑 ; 第二、能够描述业务含义,使别的程序员能够迅速了解到代码背后的信息。完全没有注释的大段代码对于阅读者形同天书,注释是给自己看的,即使隔很长时间,也能清晰理解当时的思路 ; 注释也是给继任者看的,使其能够快速接替自己的工作
- 【参考】好的命名、代码结构是自解释的,注释力求精简准确、表达到位。避免出现注释的一个极端:过多过滥的注释,代码的逻辑一旦修改,修改注释又是相当大的负担
- 【参考】特殊注释标记,请注明标记人与标记时间。注意及时处理这些标记,通过标记扫描,经常清理此类标记
- todo
- fixme
前后端规约
- 【强制】API规范
- 协议:生产环境必须使用 HTTPS。
- 路径:每一个 API 需对应一个路径,表示 API 具体的请求地址:
- 代表一种资源,只能为名词,推荐使用复数,不能为动词,请求方法已经表达动作意义。
- URL 路径不能使用大写,单词如果需要分隔,统一使用下划线。
- 路径禁止携带表示请求内容类型的后缀,比如".json",".xml",通过 accept 头表达即可。
- 请求方法:对具体操作的定义,常见的请求方法如下:
- GET:从服务器取出资源。
- POST:在服务器新建一个资源。
- PUT:在服务器更新资源。
- DELETE:从服务器删除资源。
- 请求内容:URL 带的参数必须无敏感信息或符合安全要求;body 里带参数时必须设置 Content-Type。
- 响应体:响应体 body 可放置多种数据类型,由 Content-Type 头来确定
- 【强制】前后端数据列表相关的接口返回,如果为空,则返回空数组[]或空集合{}
- 【强制】服务端发生错误时,返回给前端的响应信息必须包含 HTTP 状态码,errorCode、errorMessage、用户提示信息四个部分
- 【强制】在前后端交互的 JSON 格式数据中,所有的 key 必须为小写字母开始的lowerCamelCase 风格
- 【强制】errorMessage 是前后端错误追踪机制的体现,可以在前端输出到 type="hidden"文字类控件中,或者用户端的日志中
- 【强制】对于需要使用超大整数的场景,服务端一律使用 String 字符串类型返回,禁止使用Long 类型
- 【强制】HTTP 请求通过 URL 传递参数时,不能超过 2048 字节
- 【强制】HTTP 请求通过 body 传递内容时,必须控制长度,超出最大长度后,后端解析会出错
- 【强制】在翻页场景中,用户输入参数的小于 1,则前端返回第一页参数给后端;后端发现用户输入的参数大于总页数,直接返回最后一页
- 【强制】服务器内部重定向必须使用 forward;外部重定向地址必须使用 URL 统一代理模块生成,否则会因线上采用 HTTPS 协议而导致浏览器提示“不安全”,并且还会带来 URL 维护不一致的问题
- 【推荐】服务器返回信息必须被标记是否可以缓存,如果缓存,客户端可能会重用之前的请求结果
- 【推荐】服务端返回的数据,使用 JSON 格式而非 XML
- 【推荐】前后端的时间格式统一为"yyyy-MM-dd HH:mm:ss",统一为 GMT
- 【参考】在接口路径中不要加入版本号,版本控制在 HTTP 头信息中体现,有利于向前兼容
其他
- 【强制】在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度
- 【强制】避免用 Apache Beanutils 进行属性的 copy
- 【强制】注意 Math . random() 这个方法返回是 double 类型,注意取值的范围 0 ≤ x < 1 ( 能够取到零值,注意除零异常 )
- 【推荐】不要在视图模板中加入任何复杂的逻辑
- 【推荐】不任何数据结构的构造或初始化,都应指定大小,避免数据结构无限增长吃光内存
异常日志
错误码
- 【强制】错误码的制定原则:快速溯源、沟通标准化
- 【强制】错误码不体现版本号和错误等级信息
- 【强制】全部正常,但不得不填充错误码时返回五个零:00000
- 【强制】错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号
- 前1位代表来源 后4位代表类型
- 【强制】编号不与公司业务架构,更不与组织架构挂钩,以先到先得的原则在统一平台上进行,审批生效,编号即被永久固定
- 【强制】编号不与公司业务架构,更不与组织架构挂钩,以先到先得的原则在统一平台上进行,审批生效,编号即被永久固定
- 【强制】错误码使用者避免随意定义新的错误码
- 【强制】错误码不能直接输出给用户作为提示信息使用
- 【推荐】错误码之外的业务独特信息由 error_message 来承载,而不是让错误码本身涵盖过多具体业务属性
- 【推荐】在获取第三方服务错误码时,向上抛出允许本系统转义,将错误来源进行转换 并附带原来的错误码
- 【参考】错误码的后三位编号与 HTTP 状态码没有任何关系
- 【参考】错误码有利于不同文化背景的开发者进行交流与代码协作
- 【参考】错误码即人性,感性认知+口口相传,使用纯数字来进行错误码编排不利于感性记忆和分类
日志
- 【强制】Java 类库中定义的可以通过预检查方式规避的 RuntimeException 异常不应该通过catch 的方式来处理,比如:NullPointerException,IndexOutOfBoundsException 等等
- 【强制】异常捕获后不要用来做流程控制,条件控制
- 【强制】catch 时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分异常类型,再做对应的异常处理
- 【强制】如果不处理异常 就不要捕获 随它由调用链抛出
- 【强制】事务场景中,抛出异常被 catch 后,如果需要回滚,一定要注意手动回滚事务
- 【强制】finally 块必须对资源对象、流对象进行关闭,有异常也要做 try-catch JDK7 可以使用try-with-resources语法
- 【强制】不要在 finally 块中使用 return
- 【强制】在调用 RPC、二方包、或动态生成类的相关方法时,捕捉异常必须使用 Throwable类来进行拦截
- 【推荐】方法的返回值可以为 null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回 null 值
- 【强制】注意NPE的产生场景
- 返回类型为基本数据类型,return 包装数据类型的对象时,自动拆箱有可能产生 NPE。
- 数据库的查询结果可能为 null。
- 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null。
- 远程调用返回对象时,一律要求进行空指针判断,防止 NPE。
- 对于 Session 中获取的数据,建议进行 NPE 检查,避免空指针。
- 级联调用 obj.getA().getB().getC();一连串调用,易产生 NPE
- 【推荐】避免直接抛出 new RuntimeException(),更不允许抛出 Exception 或者 Throwable,应使用有业务含义的自定义异常。推荐业界已定义过的自定义异常
- 【参考】对于公司外的 http/api 开放接口必须使用 errorCode;而应用内部推荐异常抛出;跨应用间 RPC 调用优先考虑使用 Result 方式,封装 isSuccess()方法、errorCode、errorMessage
日志规约
- 【强制】应用中不可直接使用日志系统 (Log 4 j 、 Logback) 中的 API ,而应依赖使用日志框架(SLF4J、JCL--Jakarta Commons Logging) 中的 API
- 【强制】所有日志文件至少保存 15 天,对于当天日志,以“应用名.log”来保存 过往日志格式为: {logname}.log.{yyyy-MM-dd}
- 【强制】应用中的扩展日志 ( 如打点、临时监控、访问日志等 ) 命名方式:appName_logType_logName.log
- 【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式
- 【强制】对于 trace / debug / info 级别的日志输出,必须进行日志级别的开关判断
- 【强制】避免重复打印日志,浪费磁盘空间,务必在日志配置文件中设置 additivity = false
- 【强制】生产环境禁止直接使用 System.out 或 System.err 输出日志或使用e.printStackTrace()打印异常堆栈
- 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字 throws 往上抛出
- 【强制】日志打印时禁止直接用 JSON 工具将对象转换成 String
- 【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志 ; 有选择地输出 info 日志;注意日志输出量
- 【推荐】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从
单元测试
- 【强制】好的单元测试必须遵FIRST原则
- 【强制】对于单元测试,要保证测试粒度足够小,有助于精确定位问题。单测粒度至多是类级别,一般是方法级别
- 【强制】核心业务、核心应用、核心模块的增量代码确保单元测试通过
- 【强制】单元测试代码必须写在如下工程目录: src/test/java
- 【推荐】单元测试的基本目标:语句覆盖率达到 70% ;核心模块的语句覆盖率和分支覆盖率都要达到 100%
- 【推荐】编写单元测试代码遵守 BCDE 原则
- B:Border,边界值测试,包括循环边界、特殊取值、特殊时间点、数据顺序等。
- C:Correct,正确的输入,并得到预期的结果。
- D:Design,与设计文档相结合,来编写单元测试。
- E:Error,强制错误信息输入(如:非法数据、异常流程、业务允许外等),并得到预期的结果
- 【推荐】对于数据库相关的查询,更新,删除等操作,使用程序插入或者导入数据的方式来准备数据
- 【推荐】和数据库相关的单元测试,可以设定自动回滚机制,不给数据库造成脏数据
- 【推荐】对于不可测的代码在适当的时机做必要的重构,使代码变得可测,避免为了达到测试要求而书写不规范测试代码
- 【推荐】在设计评审阶段,开发人员需要和测试人员一起确定单元测试范围
- 【推荐】单元测试作为一种质量保障手段,在项目提测前完成单元测试
- 【参考】为了更方便地进行单元测试,业务代码应避免以下情况
- 构造方法中做的事情过多。
- 存在过多的全局变量和静态方法。
- 存在过多的外部依赖。
- 存在过多的条件语句
安全规约
- 【强制】隶属于用户个人的页面或者功能必须进行权限控制校验
- 【强制】用户敏感数据禁止直接展示,必须对展示数据进行脱敏
- 【强制】用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定,防止 SQL 注入,禁止字符串拼接 SQL 访问数据库
- 【强制】用户请求传入的任何参数必须做有效性验证
- 【强制】禁止向 HTML 页面输出未经安全过滤或未正确转义的用户数据
- 【强制】表单、 AJAX 提交必须执行 CSRF 安全验证
- 【强制】URL 外部重定向传入的目标地址必须执行白名单过滤
- 【强制】在使用平台资源,譬如短信、邮件、电话、下单、支付,必须实现正确的防重放的机制,如数量限制、疲劳度控制、验证码校验,避免被滥刷而导致资损
- 【推荐】发贴、评论、发送即时消息等用户生成内容的场景必须实现防刷、文本内容违禁词过滤等风控策略
MySQL 规约
建表规约
- 【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是,0 表示否)
- 【强制】表名、字段名必须使用小写字母或数字 , 禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑
- 【强制】表名、字段名禁用保留字
- 【强制】主键索引名为 pk_ 字段名;唯一索引名为 uk _字段名 ; 普通索引名则为 idx _字段名
- 【强制】小数类型为 decimal,禁止使用 float 和 double
- 【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型
- 【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型
- 【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text ,独立出来一张表,用主键来对应,避免影响其它字段索引效率
- 【强制】表必备三字段:id, create_time, update_time
- 【推荐】表的命名最好是遵循“业务名称_表的作用”
- 【推荐】库名与应用名称尽量一致
- 【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释
- 【推荐】冗余字段应遵循的原则
- 不是频繁修改的字段。
- 不是唯一索引的字段。
- 不是 varchar 超长字段,更不能是 text 字段
- 【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表
- 【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度
索引规约
- 【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引
- 【强制】超过三个表禁止 join 。需要 join 的字段,数据类型保持绝对一致 ; 多表关联查询时,保证被关联的字段需要有索引
- 【强制】在 varchar 字段上建立索引时,必须指定索引长度
- 【强制】页面搜索严禁左模糊或者全模糊 可以使用搜索引擎解决
- 【推荐】如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后
- 【推荐】利用覆盖索引来进行查询操作,避免回表 覆盖索引就是直接根据索引就得到数据 不用回到表上在进行查询
- 【推荐】利用延迟关联或者子查询优化超多分页场景 通过子查询来对数据进行初步筛选 避免分页数据过大
- 【推荐】SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts最好
- consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
- ref 指的是使用普通的索引(normal index)。
- range 对索引进行范围检索
- 【推荐】建组合索引的时候,区分度最高的在最左边
- 【推荐】防止因字段类型不同造成的隐式转换,导致索引失效
SQL语句
- 【强制】不要使用 count(列名)或 count(常量)来替代 count(), count() 会统计null
- 【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1,col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0
- 【强制】当某一列的值全是 NULL 时,count(col)的返回结果为 0,但 sum(col)的返回结果为NULL
- 【强制】使用 ISNULL() 来判断是否为 NULL 值
- 【强制】代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句
- 【强制】不得使用外键与级联,一切外键概念必须在应用层解决
- 【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性
- 【强制】数据订正(特别是删除或修改记录操作)时,要先 select
- 【强制】对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定
- 【推荐】SQL 语句中表的别名前加 as,并且以 t1、t2、t3、...的顺序依次命名
- 【推荐】 in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个之内
- 【参考】因国际化需要,所有的字符存储与表示,均采用 utf 8 字符集,如果存储emoji标签 使用utf8mb4
- 【参考】 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE无事务且不触发 trigger
ORM 映射(mybatis/ibatis)
- 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明
- 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义 resultMap ;反过来,每一个表也必然有一个resultMap与之对应
- 【强制】sql. xml 配置参数使用:#{}
- 【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出
- 【强制】更新数据表记录时,必须同时更新记录对应的 update_time 字段值为当前时间
- 【推荐】不要写一个大而全的数据更新接口,执行 SQL 时,不要更新无改动的字段
- 【参考】 事务不要滥用。事务会影响数据库的 QPS,使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等
工程结构
应用分层
【推荐】分层参考架构
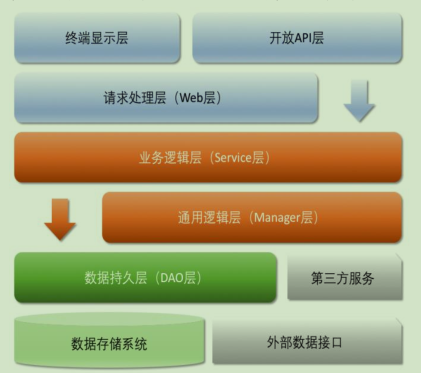
- 开放 API 层:可直接封装 Service 接口暴露成 RPC 接口;通过 Web 封装成 http 接口;网关控制层等。
- 终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染,JSP 渲染,移
动端展示等。
- Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service 层:相对具体的业务逻辑服务层。
- Manager 层:通用业务处理层,它有如下特征:
- 对第三方平台封装的层,预处理返回结果及转化异常信息,适配上层接口。
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理。
- 与 DAO 层交互,对多个 DAO 的组合复用。
- DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase、OB 等进行数据交互。
- 第三方服务:包括其它部门 RPC 服务接口,基础平台,其它公司的 HTTP 接口,如淘宝开放平台、支 付宝付款服务、高德地图服务等。
- 外部数据接口:外部(应用)数据存储服务提供的接口,多见于数据迁移场景中
- 【参考】 在 DAO 层,无法用细粒度的异常进行 catch,使用 catch(Exception e) 方式,并 throw new DAOException(e) , Service 层出现异常时,必须记录出错日志到磁盘,尽可能带上参数信息, Web 层绝不应该继续往上抛异常
- 【参考】分层领域模型规约:
- DO(Data Object):此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service 或 Manager 向外传输的对象。
- BO(Business Object):业务对象,可以由 Service 层输出的封装业务逻辑的对象。
- Query:数据查询对象,各层接收上层的查询请求。注意超过 2 个参数的查询封装,禁止使用 Map 类来传输。
- VO(View Object):显示层对象,通常是 Web 向模板渲染引擎层传输的对象
二方库依赖
- 【强制】定义 GAV 遵从以下规则
- GroupID 格式:com.{公司/BU }.业务线 [.子业务线],最多 4 级
- ArtifactID 格式:产品线名-模块名。语义不重复不遗漏
- 【强制】二方库版本号命名方式:主版本号.次版本号.修订号
- 主版本号:产品方向改变,或者大规模 API 不兼容,或者架构不兼容升级。
- 次版本号:保持相对兼容性,增加主要功能特性,影响范围极小的 API 不兼容修改。
- 修订号:保持完全兼容性,修复 BUG、新增次要功能特性等
- 【强制】线上应用不要依赖 SNAPSHOT 版本 ( 安全包除外 ) ;正式发布的类库必须先去中央仓库进行查证,使 RELEASE 版本号有延续性,且版本号不允许覆盖升级
- 【强制】二方库的新增或升级,保持除功能点之外的其它 jar 包仲裁结果不变。如果有改变,必须明确评估和验证
- 【强制】二方库里可以定义枚举类型,参数可以使用枚举类型,但是接口返回值不允许使用枚举类型或者包含枚举类型的 POJO 对象
- 【强制】依赖于一个二方库群时,必须定义一个统一的版本变量,避免版本号不一致
- 【强制】禁止在子项目的 pom 依赖中出现相同的 GroupId ,相同的 ArtifactId ,但是不同的Version
- 【推荐】底层基础技术框架、核心数据管理平台、或近硬件端系统谨慎引入第三方实现
- 【推荐】二方库不要有配置项,最低限度不要再增加配置项
- 【参考】为避免应用二方库的依赖冲突问题
- 如果依赖其它二方库,尽量是 provided 引入,让二方库使用者去依赖具体版本号
- 每个版本的变化应该被记录
服务器
- 【推荐】高并发服务器建议调小 TCP 协议的 time _ wait 超时时间
- 【推荐】调大服务器所支持的最大文件句柄数
- 【推荐】给JVM环境参数设置-XX:+HeapDumpOnOutOfMemoryError 参数
- 【推荐】线上生产环境, JVM 的 Xms 和 Xmx 设置一样大小的内存容量
设计规约
- 【强制】存储方案和底层数据结构的设计获得评审一致通过,并沉淀成为文档
- 【强制】在需求分析阶段,如果与系统交互的 User 超过一类并且相关的 User Case 超过 5 个,使用用例图来表达更加清晰的结构化需求
- 【强制】如果某个业务对象的状态超过 3 个,使用状态图来表达并且明确状态变化的各个触发条件
- 【强制】如果系统中某个功能的调用链路上的涉及对象超过 3 个,使用时序图来表达并且明确各调用环节的输入与输出
- 【强制】如果系统中模型类超过 5 个,并且存在复杂的依赖关系,使用类图来表达并且明确类之间的关系
- 【强制】如果系统中超过 2 个对象之间存在协作关系,并且需要表示复杂的处理流程,使用活动图来表示