分布式日志
传统日志收集
传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下
ELK
- elasticsearch
- logstash
- kibana
1、每台服务器集群节点安装Logstash日志收集系统插件 2、每台服务器节点将日志输入到Logstash中 3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中 4、浏览器使用安装Kibana查询日志信息
logstash配置
- logstash配置
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/home/my/elasticsearch-6.4.3/logs/elasticsearch.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "es-%{+YYYY.MM.dd}"
}
}
- 启动es
- 启动logstash
./logstash -f log.conf - 启动kibana
问题
- 每台机器就需要有一台logstash
- 非实时
使用ELK+Kafka
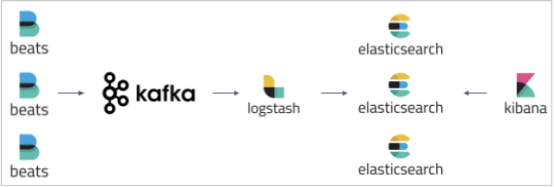
1.那些日志信息需要输入logstash (error级别) 2.AOP 异常通知 服务与服务之间如何区分日志索引文件(服务名称) 3.在分布式日志收集中,相同的服务集群的话是不需要区分日志索引文件。 4.目的为了 统一管理相同节点日志我信息。 5.相同的服务集群的话,是是不需要区分日志索引文件 搜索日志的时候,如何定位服务器节点信息呢?
同步数据库
input {
jdbc {
jdbc_driver_library => "/home/my/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.123.1:3306/shopa_member"
jdbc_user => "root"
jdbc_password => "123"
schedule => "* * * * *"
statement => "SELECT * FROM tb_user WHERE update_time >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "update_time"
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["127.0.0.1:9200"]
# 索引名称 可自定义
index => "user"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{USER_ID}"
document_type => "user"
}
stdout {
# JSON格式输出
codec => json_lines
}
}