全文检索
数据分类
- 结构化数据
- 非结构化数据
数据查询
结构化查询
非结构化查询
- 顺序扫描法
- 全文检索
索引
倒排索引:根据词找文章
| DocId | Doc |
|---|---|
| 1 | 谷歌地图之父跳槽 Facebook |
| 2 | 谷歌地图之父加盟 Facebook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟 Facebook |
| 4 | 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站 Facebook |
对这些doc进行分词之后,以词为主键,记录哪些doc出现了这些词
| WordId | Word | DocIds |
|---|---|---|
| 1 | 谷歌 | 1,2,3,4,5 |
| 2 | 地图 | 1,2,3,4,5 |
| 3 | 之父 | 1,2,4,5 |
| 4 | 跳槽 | 1,4 |
| 5 | 1,2,3,4,5 | |
| 6 | 加盟 | 2,3,5 |
| 7 | 创始人 | 3 |
| 8 | 拉斯 | 3,5 |
| 9 | 离开 | 3 |
| 10 | 与 | 4 |
| .. | .. | .. |
正排索引:根据文章找词
应用场景
- 数据量大
- 数据结构不固定
技术选型
目前开源可用的全文检索中间件只有ElasticSearch与Solr 二者都是基于Lucene
ES在许多方面都超过了Solr 所以目前只能选择ES
Lucene
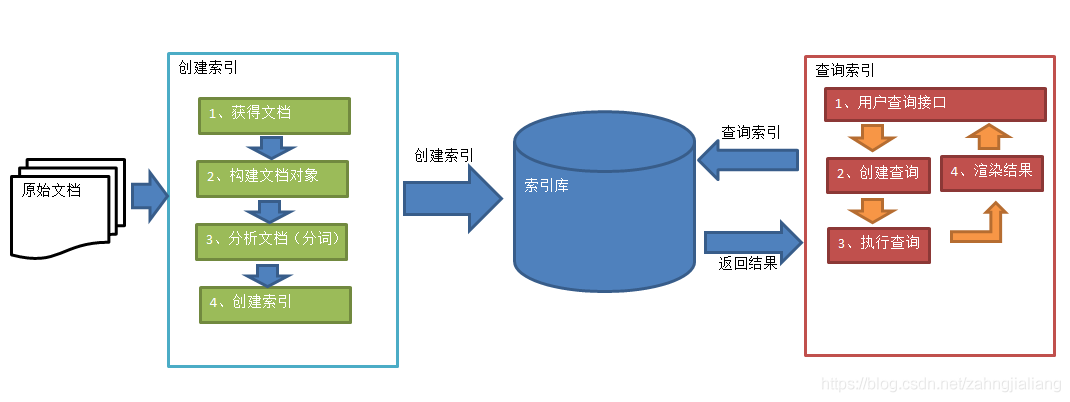
创建索引库
// 创建directory指定索引存放位置
Directory directory = FSDirectory.open(new File("./index").toPath());
IndexWriter indexWriter = new IndexWriter(directory,new IndexWriterConfig());
File dir = new File("./res");
File[] files = dir.listFiles();
assert files != null;
// 遍历文件
for (File file : files) {
String fileName = file.getName();
String filePath = file.getPath();
String content = FileUtils.readFileToString(file, "utf8");
long fileSize = FileUtils.sizeOf(file);
// 根据文件内容生成成员
Field fieldName = new TextField("name",fileName, Field.Store.YES);
Field fieldPath = new TextField("path",filePath,Field.Store.YES);
Field fieldContent = new TextField("content",content,Field.Store.YES);
Field fieldSize = new TextField("size", String.valueOf(fileSize),Field.Store.YES);
// 将成员添加到文档中
Document document = new Document();
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContent);
document.add(fieldSize);
// 将文档写入索引库
indexWriter.addDocument(document);
}
indexWriter.close();
搜索
// 创建directory指定索引存放位置
Directory directory = FSDirectory.open(new File("./index").toPath());
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
Query query = new TermQuery(new Term("content","spring"));
TopDocs docs = indexSearcher.search(query, 10);
System.out.println("总记录数:"+docs.totalHits);
ScoreDoc[] scoreDocs = docs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int id = scoreDoc.doc;
Document document = indexSearcher.doc(id);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
// System.out.println(document.get("content"));
System.out.println("--------------");
}
indexReader.close();
分析
Analyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("", "Learn how to create a web page with Spring MVC.");
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
使用别的分析器
Analyzer analyzer = new IKAnalyzer();
维护
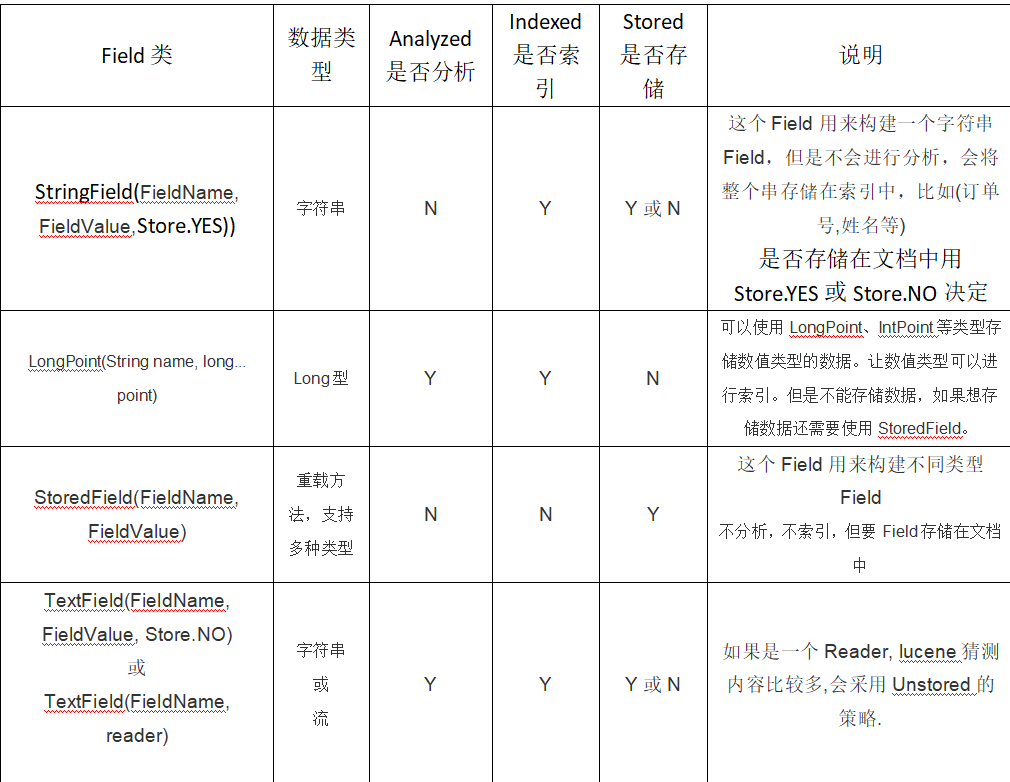
删除
Directory directory = FSDirectory.open(new File("./index").toPath());
IndexWriter indexWriter = new IndexWriter(directory,new IndexWriterConfig());
//indexWriter.deleteAll();
indexWriter.deleteDocuments(new Term("content","name"));
indexWriter.close();
更新
indexWriter.updateDocument(new Term("content","name"),document);